Author: Denis Avetisyan
A new review assesses the power of artificial intelligence to improve seasonal precipitation forecasting across the diverse landscapes of South America.

The study comprehensively evaluates LSTM, XGBoost, and other machine learning models for seasonal precipitation prediction, highlighting performance trade-offs between accuracy, computational efficiency, and the detection of extreme rainfall events.
Accurate seasonal precipitation forecasting remains a significant challenge despite advances in meteorological modeling. This study, ‘Exploring Machine Learning, Deep Learning, and Explainable AI Methods for Seasonal Precipitation Prediction in South America’, comprehensively evaluates the potential of data-driven approaches, specifically classical machine learning and deep learning techniques, for predicting precipitation patterns across South America. Results demonstrate that Long Short-Term Memory (LSTM) networks consistently outperform traditional dynamic models and offer a robust balance between accuracy and the detection of intense precipitation events, though XGBoost provides a computationally efficient alternative. Will these findings accelerate the adoption of purely data-driven methods within major climate forecasting centers globally?
The Challenge of Predicting Rainfall: A Foundation for Understanding
The ability to accurately forecast precipitation underpins critical decision-making across a surprisingly broad spectrum of sectors. Beyond the obvious implications for agriculture – optimizing irrigation and predicting yields – precise rainfall predictions are fundamental to water resource management, disaster preparedness, and even energy production via hydropower. However, achieving this accuracy remains a substantial challenge due to the inherent complexity of atmospheric processes. Precipitation isn’t simply a matter of temperature and humidity; it’s influenced by factors ranging from microscopic aerosol interactions to large-scale atmospheric circulation patterns, all interacting in non-linear ways. This complexity, coupled with limitations in observational networks and the chaotic nature of the atmosphere, means even the most sophisticated forecasting systems frequently struggle to pinpoint when, where, and how much rain will fall, particularly for localized events like convective storms. Consequently, improvements in precipitation forecasting are continually sought, driving ongoing research into advanced modeling techniques and data assimilation strategies.
Precipitation, a cornerstone of Earth’s climate system, presents a formidable modeling challenge due to the intricate, non-linear processes governing its formation. Traditional physical climate models, such as the widely-used BAM Model, often simplify these processes to reduce computational demands, inevitably leading to inaccuracies. The atmosphere’s behavior is characterized by chaotic interactions-a small change in initial conditions can yield drastically different outcomes-and current models struggle to fully represent phenomena like cloud microphysics, convective instability, and the complex interplay between atmospheric moisture, temperature, and wind patterns. These limitations result in difficulties predicting both the timing and intensity of precipitation events, particularly at regional scales, and contribute to persistent biases in long-term climate projections. Consequently, improvements in representing these non-linear dynamics are crucial for enhancing the reliability of precipitation forecasts and building more robust climate models.
Despite advancements in computational power, simulating Earth’s climate – and specifically, predicting precipitation patterns – remains intensely resource-dependent. Current physical climate models, while sophisticated, require substantial processing time and energy due to the sheer complexity of atmospheric interactions and the need for high spatial resolution. This computational burden not only limits the frequency with which models can be run and refined, but also often results in trade-offs between resolution, model physics, and ensemble size. Consequently, even with significant investment in computing infrastructure, these models frequently deliver suboptimal performance, particularly when predicting localized or extreme precipitation events, ultimately hindering the availability of timely and reliable forecasts crucial for agriculture, disaster preparedness, and water resource management.
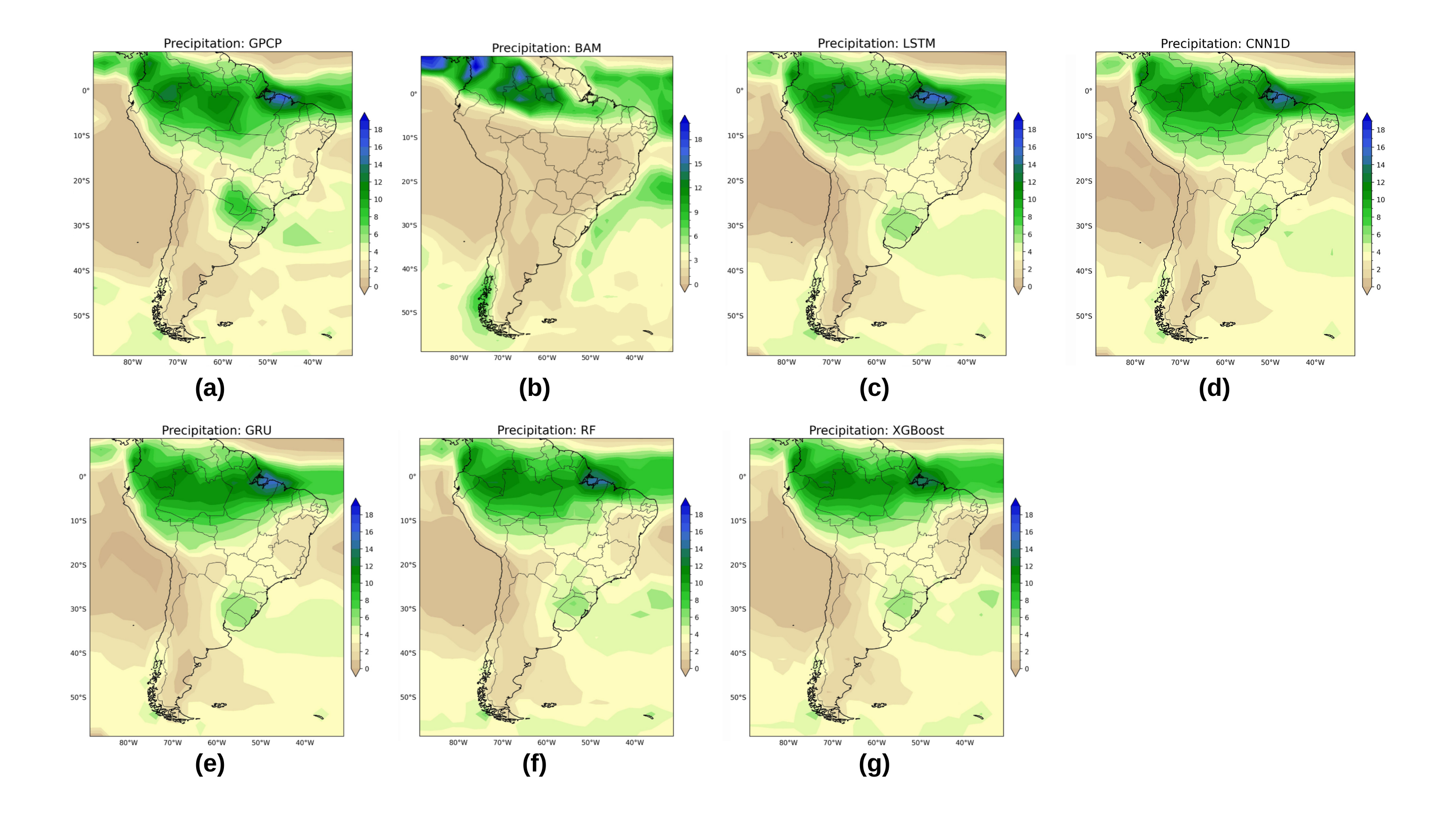
Leveraging Machine Learning: A New Approach to Forecasting
Machine learning approaches to precipitation prediction represent a significant departure from conventional numerical weather prediction systems, which rely heavily on complex physical models of atmospheric processes. Instead, these models utilize statistical learning techniques to identify correlations between historical weather variables – including temperature, humidity, wind speed, and atmospheric pressure – and subsequent precipitation events. By training on extensive datasets of past weather conditions and corresponding precipitation records, algorithms can learn to recognize patterns indicative of future rainfall or snowfall. This data-driven approach allows for the potential to capture non-linear relationships and improve forecast accuracy, particularly for short-term predictions and localized events where the computational cost of physics-based models can be prohibitive. The efficacy of these models is directly tied to the quantity and quality of the historical data used for training and validation.
Several machine learning models are currently utilized to enhance precipitation forecasting. The Random Forest Model, an ensemble learning method, excels at capturing non-linear relationships within datasets and provides robust predictions with reduced overfitting. Convolutional Neural Network 1D (CNN 1D) models are effective at identifying spatial patterns in sequential precipitation data. XGBoost, a gradient boosting algorithm, is known for its speed and efficiency, particularly with large datasets, and often achieves high predictive accuracy. Long Short-Term Memory (LSTM) networks, a type of recurrent neural network, are designed to process temporal dependencies and are well-suited for capturing the time-series characteristics of precipitation events; each model demonstrates varying degrees of success depending on the specific geographic location, temporal resolution, and available data.
Machine learning models used for precipitation prediction require extensive, high-quality observational datasets for both training and validation phases. The Global Precipitation Climatology Project (GPCP) Data provides a long-term, globally complete record of precipitation, derived from multiple satellite and surface observations, serving as a key input for model learning. Complementing this, the NCEP-NCAR Reanalysis 1 dataset offers a consistent, gridded analysis of atmospheric variables – including temperature, humidity, and wind – over several decades. This reanalysis data is crucial for understanding the atmospheric conditions leading to precipitation events and for verifying the model’s ability to accurately represent those conditions. The accuracy and reliability of these datasets directly impact the performance and predictive skill of the machine learning models.

Quantifying Predictive Skill: Evidence from Model Evaluation
Model performance evaluation utilized several quantitative metrics to assess forecasting accuracy and reliability. $R^2$ (R-squared) indicates the proportion of variance in the dependent variable explained by the model, ranging from 0 to 1, with higher values indicating a better fit. Mean Squared Error (MSE) calculates the average squared difference between predicted and actual values, where lower values represent improved accuracy. Probability of Detection (POD) measures the ability of the model to correctly identify events, while False Alarm Rate (FAR) quantifies the proportion of incorrect positive predictions; both POD and FAR are expressed as values between 0 and 1, with optimal performance characterized by high POD and low FAR.
The Long Short-Term Memory (LSTM) model exhibited strong predictive capabilities in precipitation forecasting, specifically during the spring season. Quantitative evaluation revealed an R-squared ($R^2$) value of 0.93, indicating that 93% of the variance in precipitation data is explained by the model. Furthermore, the Mean Squared Error (MSE) was measured at 0.43, representing the average squared difference between predicted and observed precipitation values and indicating a low level of error in the model’s predictions during this period.
The XGBoost model achieved a performance level of $R^2$ = 0.92 and a Mean Squared Error (MSE) of 0.62 during winter season evaluation. Notably, XGBoost exhibited a latency of 4.2348 milliseconds, indicating a comparatively rapid processing time. This combination of high accuracy, as measured by $R^2$ and MSE, coupled with low latency, suggests that XGBoost offers a practical balance between predictive power and computational efficiency for real-time or near real-time forecasting applications.
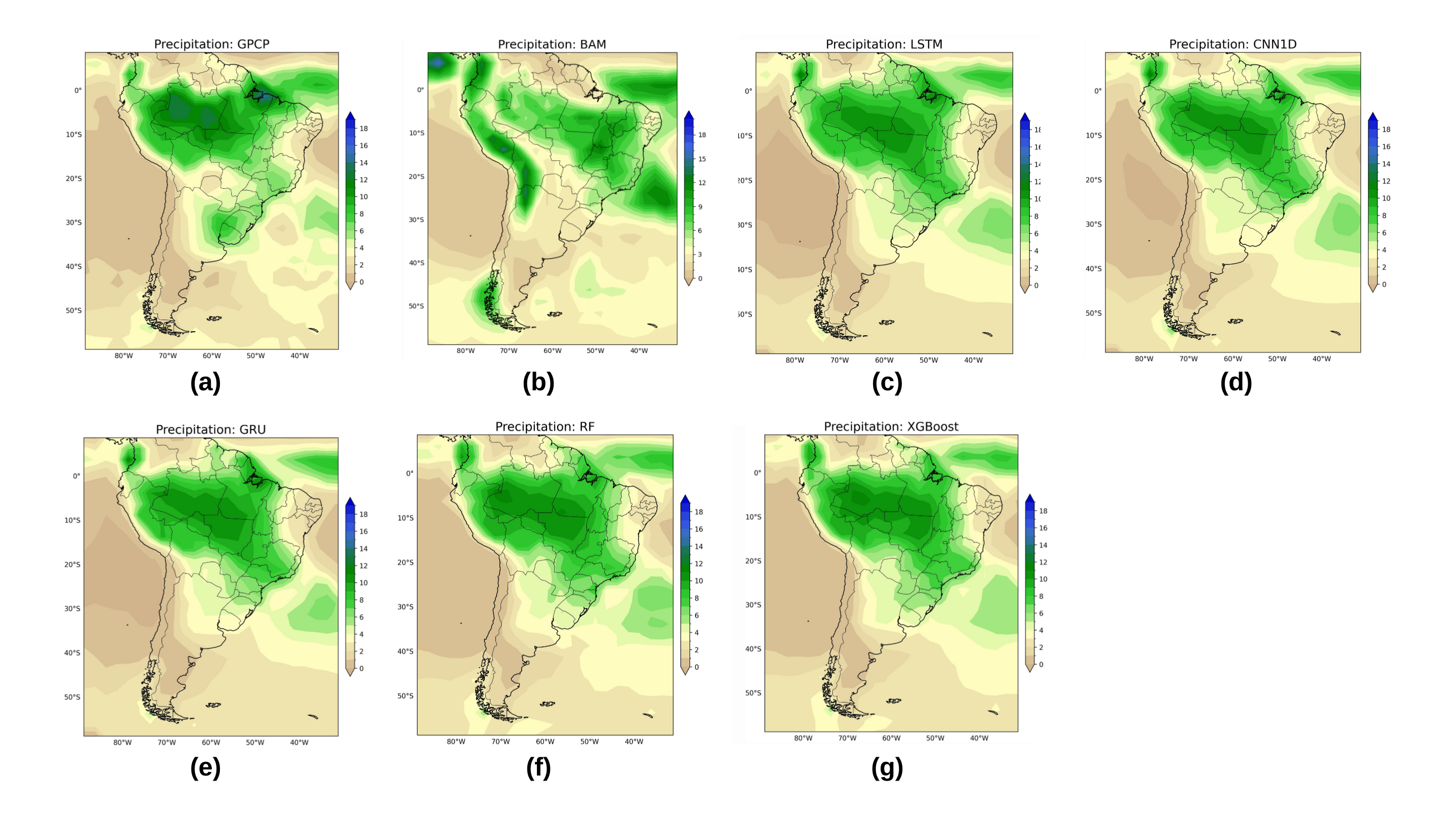
Unveiling the ‘Why’: Interpreting Model Behavior with SHAP Values
To decipher the complex relationships driving precipitation forecasts, SHAP (SHapley Additive exPlanations) values were instrumental in interpreting the predictions of both the LSTM and CNN 1D models. This technique, rooted in game theory, assigns each input feature a value representing its contribution to a specific prediction, effectively revealing which atmospheric variables exerted the most influence. The analysis demonstrated that variables such as temperature at various altitudes, humidity levels, and wind shear consistently ranked as the most important predictors, while others played a comparatively minor role. By quantifying these feature contributions, SHAP values not only illuminate the model’s internal logic but also offer climate scientists a more nuanced understanding of the atmospheric dynamics governing rainfall patterns, paving the way for improved forecasting accuracy and targeted climate research.
The application of SHAP values didn’t merely explain how the LSTM and CNN 1D models predicted precipitation, but crucially, it illuminated which atmospheric variables exerted the most influence on those predictions. Analyses revealed that factors like dew point, specific humidity, and geopotential height at various altitudes consistently ranked as the strongest drivers of precipitation patterns within the model. This granular understanding offers climate scientists a powerful tool for validating model behavior against established meteorological principles, and potentially refining predictive accuracy by focusing on the most critical input features. Furthermore, the identification of these key variables allows for a more targeted investigation of atmospheric processes, enhancing the ability to forecast and ultimately prepare for extreme weather events.
A thorough examination of the LSTM and CNN 1D models’ internal logic, facilitated by SHAP values, doesn’t simply offer predictions about precipitation; it elucidates why those predictions are made. This transparency is crucial for establishing trust in the models’ outputs, allowing climate scientists to move beyond simply accepting a forecast to understanding the underlying rationale. By pinpointing which atmospheric variables most strongly influence the model’s decisions – and conversely, which have minimal impact – researchers can refine the model’s architecture, potentially incorporating additional relevant data or streamlining calculations. This iterative process of explanation and improvement ultimately leads to more robust and reliable predictions, fostering greater confidence in the models’ ability to inform crucial climate-related decisions and further the understanding of complex weather patterns.
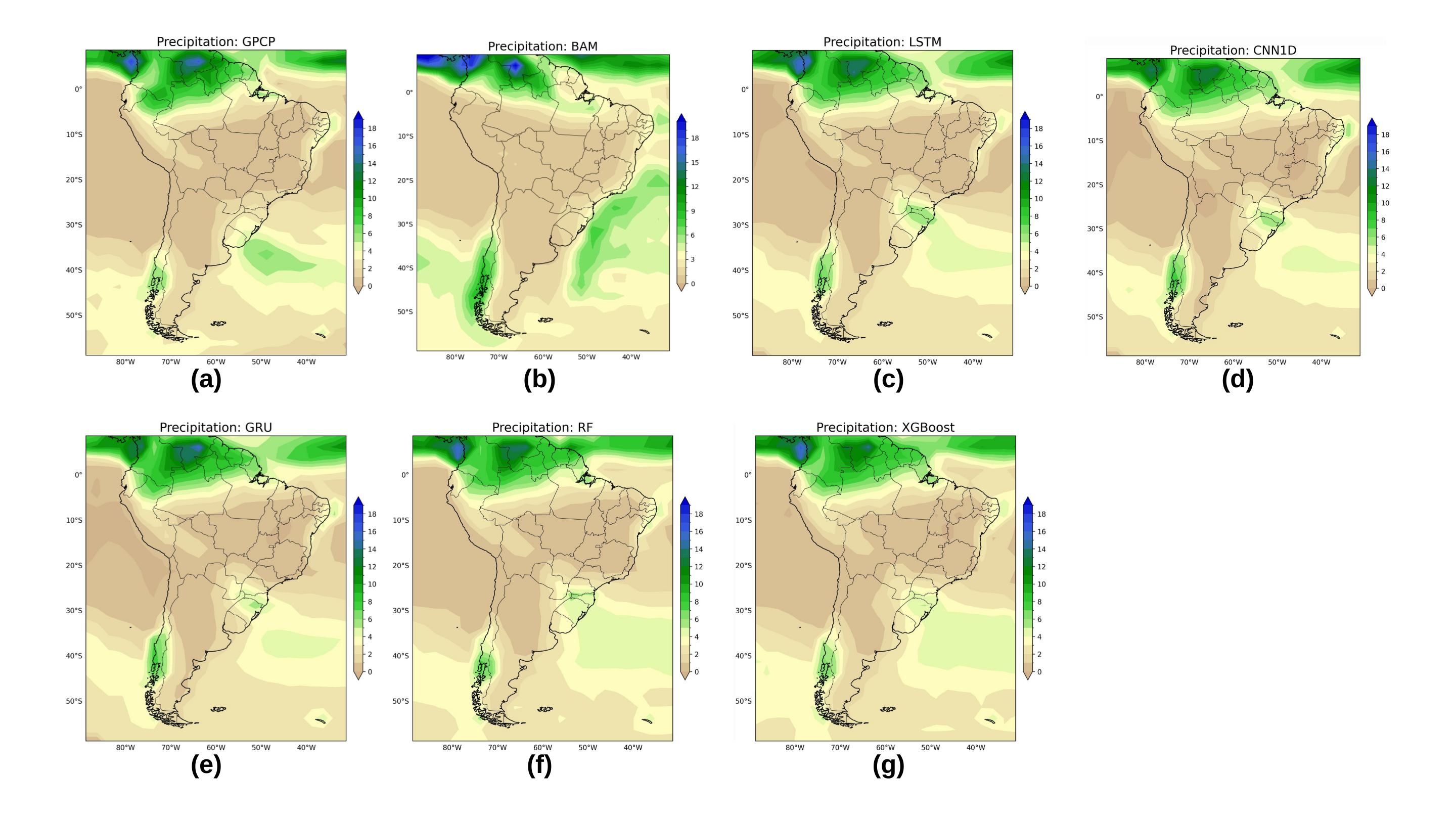
Toward Robust Seasonal Forecasts: Charting Future Directions
Accurate seasonal climate prediction hinges critically on the ability to forecast precipitation patterns, as rainfall and snowfall dictate water resource availability, agricultural yields, and the risk of extreme events. Improved precipitation forecasting isn’t merely a refinement of meteorological science; it’s a fundamental requirement for proactive disaster risk reduction and climate change adaptation. Reliable predictions allow communities and governments to implement timely mitigation strategies – from bolstering flood defenses and managing reservoir levels to enacting drought preparedness plans and optimizing irrigation schedules. Beyond immediate responses to hazards, enhanced precipitation forecasts enable long-term planning for sustainable water management, food security, and resilient infrastructure, ultimately minimizing the socio-economic impacts of a changing climate and safeguarding vulnerable populations.
The future of seasonal climate prediction lies in a synergistic approach, combining the established rigor of physical climate models with the pattern-recognition capabilities of machine learning. Physical models, grounded in fundamental physics, excel at simulating long-term climate dynamics but can struggle with computational demands and representing complex, non-linear processes. Machine learning, conversely, can efficiently identify subtle relationships within vast datasets and improve short-term forecasting, yet often lacks a clear basis in physical laws. By integrating these approaches – perhaps through machine learning models that refine physical model outputs or by using machine learning to parameterize unresolved processes – researchers aim to create a new generation of climate models that are both accurate and computationally feasible. This integration promises not only enhanced predictive skill, particularly for phenomena like precipitation, but also a more nuanced understanding of the climate system itself, paving the way for more effective adaptation and mitigation strategies.
The practical utility of increasingly complex climate models hinges not simply on their predictive skill, but on the ability to understand why they generate specific forecasts. Advancements in model interpretability and explainability are therefore paramount, moving beyond ‘black box’ predictions to reveal the key drivers and underlying mechanisms influencing seasonal climate projections. This transparency fosters trust among stakeholders – from policymakers and emergency managers to agricultural planners – enabling them to confidently integrate forecasts into proactive decision-making processes. Crucially, understanding the model’s reasoning allows for the identification of potential biases or limitations, facilitating targeted improvements and ensuring responsible application of climate information in a world facing escalating climate risks. Without this crucial step toward explainable AI, even highly accurate forecasts risk being underutilized or misinterpreted, diminishing their potential to mitigate the impacts of a changing climate.

The pursuit of accurate seasonal precipitation forecasting, as demonstrated by this study’s evaluation of LSTM and XGBoost models, often leads to increasing complexity. However, the core finding-LSTM’s consistent performance alongside XGBoost’s efficiency-highlights a principle of parsimony. As Claude Shannon observed, “The most important thing in communication is to convey the message with the least possible distortion.” Similarly, this research suggests that the most valuable predictive models aren’t necessarily the most intricate; rather, they effectively convey the information-in this case, precipitation patterns-with minimal unnecessary complexity. The balance achieved between accuracy and computational cost embodies an elegant solution, aligning with the notion that simplicity is indeed the hallmark of intelligence.
Further Horizons
The pursuit of predictive accuracy, while persistent, reveals diminishing returns. This work, establishing LSTM and XGBoost as competent tools, does not solve seasonal precipitation forecasting. It refines the question. The core limitation remains: a fundamental inability to model chaotic systems with complete fidelity. Focus shifts, then, from brute-force prediction to probabilistic forecasting-quantifying uncertainty with greater precision.
Computational efficiency, demonstrated by XGBoost, is not merely a technical detail. It is an ethical imperative. Complex models, however accurate in principle, are useless if they cannot deliver timely insights. Future work must prioritize streamlined architectures, potentially incorporating physics-informed machine learning-a gentle nudge toward first principles, tempering the data-driven approach.
Explainability, addressed through SHAP values, remains a critical, largely unresolved challenge. Clarity is the minimum viable kindness. Knowing that a model predicts rainfall is insufficient. Understanding why-identifying the causal relationships within a vast, interconnected system-is the true measure of progress. The field moves, necessarily, toward interpretable AI-models that yield not just predictions, but insight.
Original article: https://arxiv.org/pdf/2512.13910.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- Trading Smarter: AI-Powered Execution Schedules
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
- 15 Films That Were Shot Entirely on Phones
2025-12-17 16:26