Author: Denis Avetisyan
A new analysis frames the strengths and weaknesses of transformer models through the principles of graph neural networks, shedding light on their internal workings.

This review identifies information propagation bottlenecks like over-smoothing and over-squashing, and examines how causal masking impacts positional understanding in transformer architectures.
Despite the remarkable success of transformer architectures in modern large language models, their failure modes remain poorly understood and often lead to unpredictable performance degradation. This paper, ‘Understanding the Failure Modes of Transformers through the Lens of Graph Neural Networks’, investigates these limitations by drawing parallels to the well-established theory of information propagation in graph neural networks. We demonstrate that issues like over-smoothing, over-squashing, and the unique constraints of causal masking in decoder-only transformers create bottlenecks and biases in information flow. Ultimately, this analysis offers a more theoretically grounded perspective on existing mitigation strategies and suggests avenues for developing targeted improvements to address specific transformer vulnerabilities-but can this interdisciplinary approach unlock a truly robust and interpretable LLM architecture?
The Inherent Limits of Sequential Thought
Contemporary deep learning architectures, most notably Transformers, have achieved remarkable success by processing information sequentially – treating data as a series of steps. However, this approach encounters limitations when dealing with complex relational data, where the connections between data points are as important as the data itself. While effective for tasks like natural language processing where sequential order is inherent, these models struggle to efficiently represent and reason about information best described as a graph – a network of interconnected entities. The sequential nature forces a flattening of these relationships, requiring extensive computation to infer connections that are explicitly defined in graph structures. This inherent mismatch between the sequential processing paradigm and the relational nature of the data ultimately hinders performance and scalability when tackling problems demanding an understanding of intricate connections, such as knowledge graphs, social networks, or molecular interactions.
The inherent linearity of sequential processing creates significant inefficiencies when dealing with data possessing complex relationships. Many real-world datasets, such as social networks, molecular structures, and knowledge graphs, are naturally represented as graphs – interconnected nodes rather than linear sequences. Attempting to force this graph-structured information into a sequential format, as often occurs with Transformers, necessitates breaking down relationships and losing crucial contextual information. This process not only increases computational burden but also hinders the model’s ability to effectively reason about the underlying data; discerning connections and patterns within a graph requires navigating these relationships directly, a task for which sequential models are ill-equipped. Consequently, performance suffers, and the potential for insightful analysis is diminished when complex relational data is subjected to the constraints of sequential processing.
The fundamental limitation of many current deep learning architectures lies not in their ability to process data, but in how they combine it. Traditional methods typically rely on sequentially layering operations, effectively treating information as a linear progression – a process that struggles with the inherent complexity of relational data. This approach lacks a robust framework for managing information flow, meaning critical connections and dependencies can be lost or diminished as data moves through the network. Consequently, models often fail to effectively capture the nuanced relationships between different data points, hindering their performance on tasks requiring complex reasoning or an understanding of interconnected systems. A more dynamic and flexible approach to information integration is therefore crucial for advancing the capabilities of artificial intelligence, allowing models to move beyond linear processing and embrace the full richness of relational information.

The Perils of Oversimplification: Smoothing and Squashing
Over-smoothing in Graph Neural Networks (GNNs) and Transformers arises from the iterative process of message passing or attention, where node representations aggregate information from their neighbors. With each successive layer, nodes increasingly share similar feature vectors, diminishing their distinctiveness and hindering the network’s ability to differentiate between them. This homogenization occurs because repeated aggregation diffuses information across the graph or sequence, effectively averaging out unique node characteristics. Consequently, distant nodes may exhibit similar representations, reducing the model’s capacity to capture fine-grained structural information or subtle distinctions within the input data. The extent of over-smoothing is influenced by factors such as network depth, aggregation function, and the inherent properties of the graph or sequence being processed.
Over-squashing in neural networks refers to the phenomenon where successive layers compress information into fixed-size vector representations, potentially discarding critical details from the input data. This compression occurs as information is funneled through bottlenecks, such as fully connected layers or pooling operations, where higher-dimensional input features are mapped to lower-dimensional spaces. The resulting loss of information can hinder the network’s ability to discriminate between subtle differences in the input, ultimately impacting performance. The ‘Spectral Gap’ ($\lambda_1$) can serve as a quantifiable proxy for the degree of over-squashing present in a network’s architecture, with smaller gaps indicating greater information compression and potential loss.
Quantitative analysis of over-smoothing and over-squashing utilizes specific metrics to identify architectural vulnerabilities in Graph Neural Networks and Transformers. Over-smoothing is assessed via ‘Dirichlet Energy’ ($δDE = 1/N ∑_{i}∑_{j∈Ni} ||Hi(l) – Hj(l)||₂²$), where lower values correspond to increased homogenization of node representations. Analysis of the Jacobian Matrix, specifically examining the bound $∂hi(r+1)/xs ≤ (αβ)^(r+1) (Ar+1)is$, reveals how input sensitivities diminish through successive layers. Here, $hi$ represents the hidden state, $xs$ is the input, and the terms $α$, $β$, and $Ar+1$ relate to network parameters and structure; a rapidly decreasing sensitivity indicates information loss. These metrics provide objective measurements to pinpoint areas where network architecture hinders effective information propagation.
Effective Resistance, a concept originating in electrical network theory, offers a method for analyzing information flow bottlenecks within graph structures; it quantifies the difficulty of signal propagation between nodes, with higher resistance indicating restricted information transfer. This metric directly relates to over-smoothing, as high resistance paths impede message passing and contribute to node representation homogenization. Complementarily, the Spectral Gap, denoted as $λ_1$, of the graph Laplacian serves as a proxy for quantifying over-squashing; a larger spectral gap indicates better preservation of signal information and reduced compression of node features into fixed-size vectors. Specifically, a smaller $λ_1$ suggests a greater tendency for information loss during embedding, contributing to the over-squashing phenomenon where crucial details are lost during representation learning.
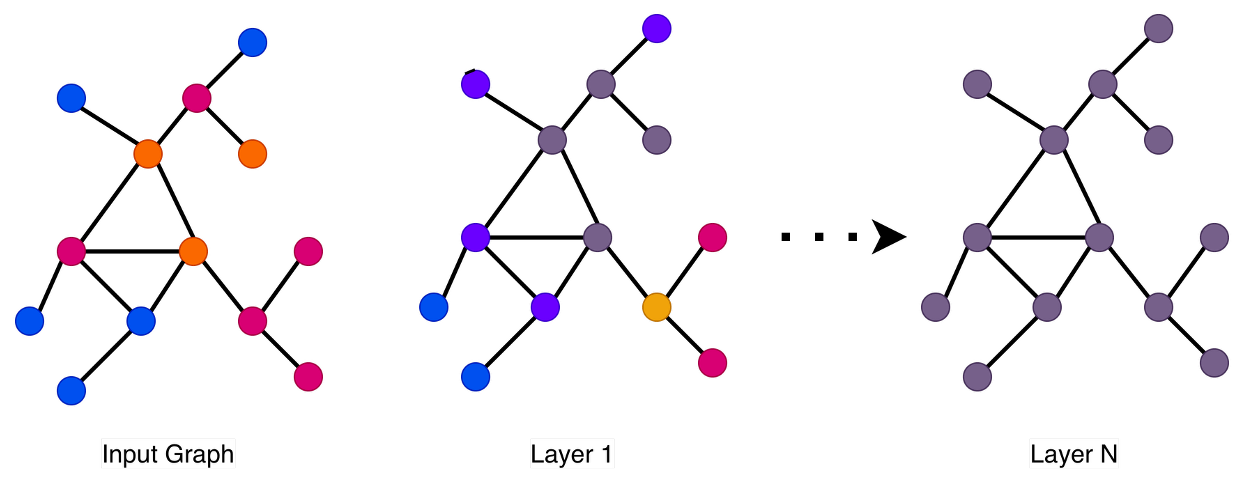
Mitigating the Bottleneck: Attention and Masking Strategies
The Self-Attention mechanism, central to Transformer architectures, calculates relationships between all input tokens to weigh their importance. However, this process can be prone to ‘Attention Sink’ phenomena, where the model disproportionately focuses on easily identifiable, but potentially irrelevant, tokens. This occurs because the attention weights are learned during training and can become biased towards superficial features or tokens with high initial salience. Consequently, the model may fail to adequately process and integrate information from all input tokens, hindering its ability to perform true relational reasoning – accurately identifying and utilizing the relationships between different elements within the data – and limiting performance on tasks requiring nuanced understanding of context.
Causal masking, a standard practice in decoder-only transformer architectures such as those used in large language models, prevents the model from attending to future tokens during training and inference, thereby avoiding information leakage. However, this unidirectional attention creates the ‘Runway Problem’ wherein tokens at the beginning of a sequence receive fewer refinement opportunities compared to those appearing later. Specifically, early tokens are only informed by the initial embedding and subsequent self-attention layers processing preceding tokens, while later tokens benefit from attention applied to the entire preceding sequence, effectively creating an asymmetry in the iterative refinement process. This disparity can hinder the model’s ability to accurately represent and process information contained within the initial portion of the input sequence, impacting overall performance on tasks requiring complete contextual understanding.
Pause Tokens represent a technique designed to mitigate limitations in decoder-only Transformer architectures related to the ‘Runway Problem’. These tokens are inserted into the input sequence, creating explicit gaps in processing. This allows the model to revisit and refine previously generated content with additional computational steps, effectively increasing the opportunities for information propagation and refinement beyond the standard sequential processing. By providing this extra space, Pause Tokens aim to improve the model’s ability to capture long-range dependencies and address the unequal refinement opportunities inherent in causal masking, potentially leading to enhanced performance on tasks requiring complex relational reasoning.
The Differential Transformer utilizes a subtractive attention map to refine the attention mechanism and enhance performance. Instead of directly computing attention weights, it calculates the difference between two attention maps: one generated from the current hidden state and another from a previous, denoised state. This subtraction process effectively isolates and removes noise within the attention distribution, focusing the model on more relevant relationships. By subtracting unwanted attention signals, the Differential Transformer aims to improve the clarity and precision of information propagation, leading to better results, particularly in tasks susceptible to noisy input or ambiguous context. The resulting attention map is then used for weighted aggregation of input features, as in a standard Transformer architecture.
A Unified Perspective: The Essence of Information Mixing
A compelling perspective is emerging in deep learning that frames the field around the principle of ‘Information Mixing’. This concept posits that the success of various architectures-from convolutional networks to transformers-hinges on their ability to effectively combine and propagate data representations. Rather than viewing these models as disparate entities, information mixing suggests they all operate by iteratively blending information from different sources, allowing the network to build increasingly complex and abstract understandings of the input. The strength of this mixing-how well information is integrated and distributed-directly correlates with a model’s capacity to learn intricate patterns and generalize to unseen data. Consequently, focusing on optimizing this fundamental mixing process offers a potentially unifying framework for advancing the entire field, moving beyond architecture-specific improvements towards a deeper understanding of learning itself.
The capacity of both Graph Neural Networks and Deep Sets to model intricate relationships hinges on a principle known as effective information mixing. These architectures don’t simply process individual data points in isolation; instead, they actively combine and propagate information between them. In Graph Neural Networks, this manifests as message passing along the edges of a graph, allowing nodes to aggregate features from their neighbors. Similarly, Deep Sets employ permutation-invariant functions to combine the features of their constituent elements. The success of both approaches relies on this ability to synthesize information from diverse sources, enabling the model to learn representations that capture the underlying structure and dependencies within the data. Without efficient mixing, these models struggle to discern meaningful patterns, highlighting its critical role in their learning process and overall performance.
A persistent limitation in both Graph Neural Networks and Deep Sets lies in the phenomenon of ‘Under-Reaching,’ which hinders effective information dissemination throughout the entire structure. This occurs when signals attenuate over distance, preventing nodes or elements far apart from influencing each other during the learning process. Consequently, the model struggles to capture long-range dependencies crucial for understanding complex relationships within the data. While these architectures excel at processing local information, the inability to efficiently propagate signals across extended paths restricts their capacity for robust reasoning and generalization, particularly in scenarios requiring global context or the integration of distant features. Addressing this challenge necessitates innovative techniques for enhancing signal persistence and overcoming the inherent limitations of distance-based attenuation within these networks.
The capacity for a deep learning model to perform robust reasoning and achieve broad generalization hinges critically on its ability to effectively mix information. This process, where data is combined and propagated throughout the network, isn’t simply about aggregating inputs; it’s about creating a cohesive internal representation that captures complex relationships. Optimizing this mixing-adjusting how information flows, which features are prioritized, and the mechanisms for long-range dependencies-allows the model to move beyond memorization and toward true understanding. A well-tuned mixing process enables the model to identify relevant patterns, disregard noise, and apply learned knowledge to novel situations, ultimately fostering adaptability and reliable performance across a diverse range of tasks. Consequently, advancements in this area are paramount to unlocking the full potential of deep learning architectures.

The study of transformer architectures, framed through graph neural networks, reveals inherent limitations in information propagation. The observed phenomena of over-smoothing and over-squashing demonstrate how systems, even those achieving state-of-the-art performance, are susceptible to decay as information traverses the network. This echoes Ken Thompson’s sentiment: “Software is like entropy: It is difficult to stop it from increasing.” The research highlights how positional encodings, while intending to provide context, introduce a bias – a form of ‘latency’ in the system’s understanding – mirroring the unavoidable ‘tax every request must pay’ in complex computation. Ultimately, the work suggests that even the most sophisticated architectures are not immune to the fundamental principles governing all systems: a gradual loss of signal and increasing complexity over time.
What Lies Ahead?
The exercise of framing transformers as graph neural networks, as this work demonstrates, isn’t simply a re-interpretation, but a necessary excavation. Every commit is a record in the annals, and every version a chapter, revealing that familiar architectural choices harbor the same propagation failures seen in graph-based systems – over-smoothing, over-squashing. These aren’t new afflictions; they are inherent to any system attempting to synthesize information across distance. The attention mechanism, once lauded for its novelty, appears less a solution and more a localized treatment for a systemic ailment.
Future iterations will likely focus not on avoiding these limitations – for they are unavoidable – but on managing their decay. Causal masking, while improving sequential modeling, introduces a position bias, a subtle tax on ambition. Mitigating this will require a deeper understanding of how positional information is encoded and propagated, perhaps drawing on insights from network science regarding node centrality and influence. The question isn’t whether transformers will fail, but how gracefully they will age.
Delaying fixes is a tax on ambition. The current trajectory suggests a refinement of existing techniques-novel attention variants, more efficient masking strategies. However, a truly disruptive approach might necessitate abandoning the sequential metaphor entirely, seeking alternative frameworks that address information propagation at a more fundamental level. The longevity of these architectures will depend on acknowledging these limitations, and not attempting to mask them with incremental improvements.
Original article: https://arxiv.org/pdf/2512.09182.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- 🚨 Kiyosaki’s Doomsday Dance: Bitcoin, Bubbles, and the End of Fake Money? 🚨
- Monster Hunter Stories 3: Twisted Reflection launches on March 13, 2026 for PS5, Xbox Series, Switch 2, and PC
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Crypto’s Comeback? $5.5B Sell-Off Fails to Dampen Enthusiasm!
- 39th Developer Notes: 2.5th Anniversary Update
- 10 Hulu Originals You’re Missing Out On
- 10 Underrated Films by Ben Mendelsohn You Must See
2025-12-11 10:35