Author: Denis Avetisyan
A new open-source large language model, DeepSeek-V3.2, is closing the performance gap with proprietary systems through innovations in model architecture and training techniques.

DeepSeek-V3.2 leverages sparse attention, reinforcement learning, and extensive agentic task training to achieve competitive results on a range of benchmarks.
Despite rapid advances in large language models, achieving both superior performance and computational efficiency remains a significant challenge. This paper introduces DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, detailing a new open-source model that rivals-and in some cases surpasses-closed-source alternatives like GPT-5 and Gemini-3.0-Pro through innovations in sparse attention, scalable reinforcement learning, and large-scale agentic task synthesis. Notably, DeepSeek-V3.2 demonstrates gold-medal level reasoning abilities on challenging benchmarks like the International Mathematical and Informatics Olympiads. Could this model represent a pivotal step towards democratizing access to state-of-the-art AI capabilities?
Reasoning’s Bottleneck: Beyond Scale and Into Efficiency
Despite their remarkable abilities in generating human-quality text, conventional language models frequently falter when confronted with reasoning challenges that demand extended, step-by-step thought processes. These models, often trained on vast datasets to predict the next word in a sequence, excel at pattern recognition but struggle with tasks requiring genuine inferential leaps or the consistent application of logic across multiple stages. This limitation stems from their architecture; the sheer scale of parameters doesn’t necessarily translate into improved reasoning, as models can become lost in superficial correlations rather than identifying underlying causal relationships. Consequently, complex problems-such as those involving planning, common sense, or nuanced understanding of context-often expose the boundaries of their reasoning capabilities, highlighting the need for innovative approaches beyond simply increasing model size.
The pursuit of increasingly intelligent artificial systems has largely focused on scaling – building larger and larger models trained on vast datasets. However, contemporary research indicates that simply increasing scale yields diminishing returns in complex reasoning tasks. While larger models can store more information, they don’t necessarily process it more effectively. A fundamental shift towards architectural innovation is therefore critical; designs that prioritize efficient information flow, selective attention, and hierarchical processing are needed to unlock genuine reasoning potential. This means moving beyond brute-force approaches and exploring designs that mimic the cognitive strategies of biological systems, enabling models to solve problems with fewer computational resources and greater robustness, ultimately bridging the gap between statistical learning and true understanding.
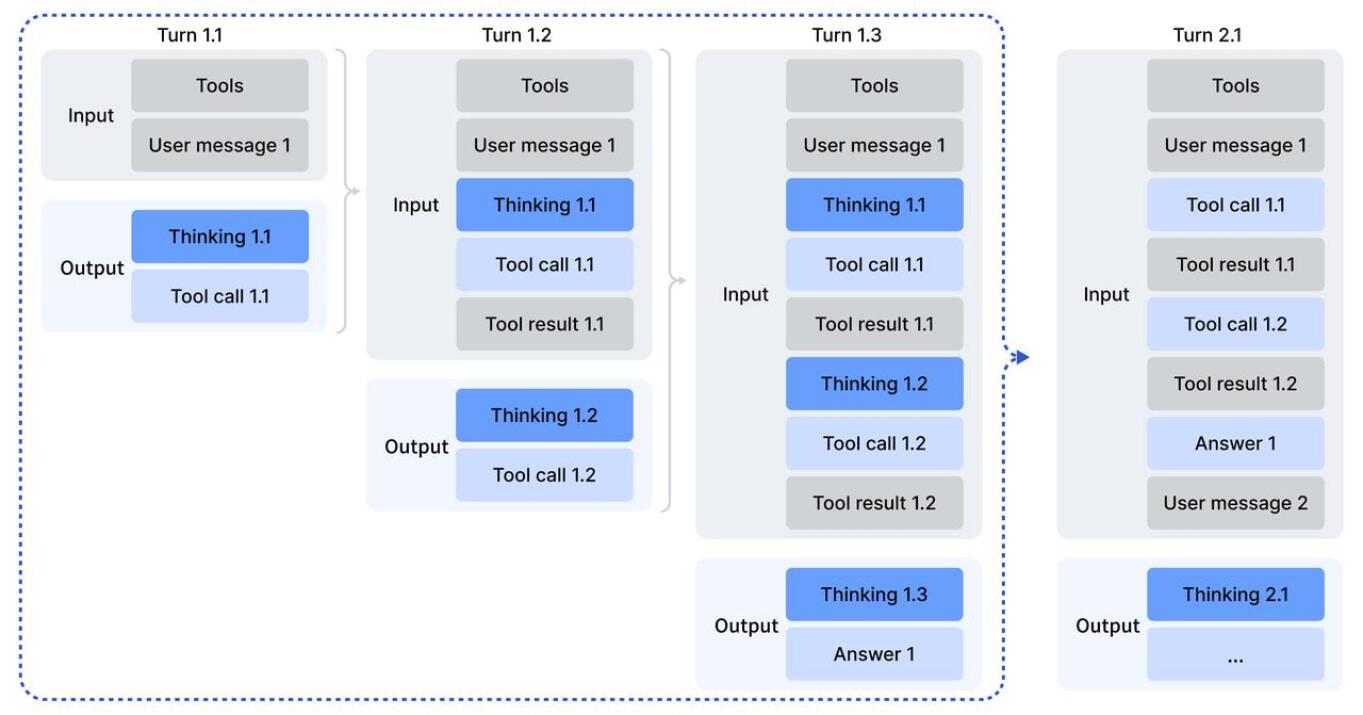
DeepSeek-V3.2: A Pragmatic Architecture for Advanced Reasoning
DeepSeek-V3.2 incorporates a Mixture-of-Experts (MLA) layer to enhance both model capacity and computational efficiency. This layer consists of multiple expert networks, each specializing in processing specific subsets of input data. A gating network dynamically routes each input token to a select few of these experts, effectively creating a conditionally-activated model. This sparse activation significantly reduces the number of parameters engaged during both training and inference, lowering computational costs compared to dense models with equivalent parameter counts. The MLA architecture allows DeepSeek-V3.2 to scale to $1.6T$ parameters while maintaining feasible training and inference speeds, and facilitates specialization for improved performance across diverse tasks.
DeepSeek Sparse Attention (DSA) addresses the computational challenges of processing long sequences by reducing the attention matrix from $O(n^2)$ to $O(n \log n)$ complexity, where n is the sequence length. This is achieved through a novel combination of techniques including locality-sensitive hashing and efficient grouping of attention weights. DSA selectively attends to the most relevant parts of the input sequence, minimizing redundant calculations without significant performance degradation. Empirical results demonstrate that DSA maintains comparable or superior performance to standard attention mechanisms on tasks requiring long context windows, while substantially reducing memory requirements and accelerating processing speeds.
The DeepSeek-V3.2 architecture employs a strategic integration of Multi-Head Attention (MHA) and Multi-Query Attention (MQA) within its Mixture-of-Experts (MLA) framework to address computational demands during both training and decoding phases. MHA is utilized to allow the model to attend to different parts of the input sequence with varying learned linear projections, enhancing representational capacity. MQA, which shares key and value projections across all heads, is then implemented to significantly reduce memory bandwidth requirements and accelerate decoding speed. This combination allows for a balance between model expressiveness and efficiency, enabling effective processing of long sequences without substantial performance degradation; specifically, MQA reduces the memory footprint from $O(N)$ to $O(1)$ during inference, where $N$ is the sequence length.

Training for True Agency: Synthetic Tasks and Reinforcement Learning
DeepSeek-V3.2’s training regimen prioritizes the development of agentic capabilities through the utilization of automatically generated Synthetic Agentic Tasks. These tasks are programmatically created to simulate real-world scenarios requiring sequential decision-making and problem-solving. The automated generation process allows for the creation of a diverse and scalable training dataset, exposing the model to a wide range of challenges without manual annotation. This approach differs from traditional supervised learning by focusing on training the model to act within an environment and optimize for specific goals, rather than simply predicting outputs based on given inputs. The synthetic tasks are designed to evaluate and improve the model’s ability to plan, execute, and adapt in dynamic situations.
DeepSeek-V3.2 employs Reinforcement Learning (RL) as a key component in enhancing its decision-making processes. This RL phase represents a significant investment, with allocated resources exceeding 10% of the model’s initial pre-training costs. This substantial budget allows for extensive training iterations and exploration of diverse scenarios, enabling the model to refine its strategies and optimize for desired outcomes in complex tasks. The RL training focuses on rewarding behaviors that align with agentic capabilities, effectively shaping the model’s policy to maximize performance and achieve specific goals within its operational environment.
Context management techniques were integrated into the DeepSeek-V3.2 architecture to enhance its ability to process extended sequences of text. These techniques effectively expand the model’s token budget, enabling it to maintain performance and coherence when dealing with input lengths significantly exceeding typical limits. Specifically, innovations in attention mechanisms and memory management allow the model to selectively focus on relevant information within long contexts, mitigating the computational challenges and information loss associated with processing lengthy sequences. This extended context window is critical for tasks requiring comprehensive understanding and reasoning over large volumes of data, such as complex document analysis and multi-turn dialogue.

Beyond the Hype: Performance Validation and Real-World Impact
Recent evaluations demonstrate that DeepSeek-V3.2 attains reasoning capabilities on par with GPT-5, a leading closed-source large language model. This achievement represents a substantial leap forward for open-source alternatives, considerably diminishing the performance disparity previously observed in complex, agentic tasks. Unlike many models requiring extensive fine-tuning for specific applications, DeepSeek-V3.2 exhibits strong zero-shot reasoning, allowing it to tackle unfamiliar problems with minimal prior examples. This narrowing gap suggests that sophisticated reasoning abilities are no longer exclusive to proprietary models, potentially accelerating innovation and accessibility in the field of artificial intelligence by empowering a wider range of developers and researchers with state-of-the-art tools.
DeepSeek-V3.2 demonstrates a remarkable capacity for navigating and synthesizing information from the web, evidenced by its 67.6% accuracy on the challenging BrowseComp benchmark. This performance, achieved utilizing a “Discard-all” strategy where irrelevant information is actively filtered, highlights the model’s robust information retrieval capabilities. Unlike systems that might struggle with extraneous data, DeepSeek-V3.2 effectively prioritizes relevant content during web browsing, enabling it to answer complex questions requiring external knowledge with considerable precision. This aptitude suggests a significant advancement in building LLMs capable of functioning as reliable and efficient research assistants, seamlessly integrating web access into their reasoning processes.
DeepSeek-V3.2-Speciale demonstrates an exceptional capacity for complex problem-solving, achieving gold medals in four prestigious international competitions – the International Olympiad in Informatics, the International Collegiate Programming Contest World Final, the International Mathematical Olympiad, and the Canadian Mathematical Olympiad – all without any specific training geared towards these challenges. This performance highlights the model’s inherent reasoning abilities and generalization capabilities, suggesting a proficiency in tackling tasks demanding algorithmic thinking, mathematical rigor, and complex logical deduction. The achievement is particularly notable as the model was not fine-tuned or optimized for competitive programming or mathematical problem-solving, indicating a powerful foundational intelligence capable of excelling in domains beyond its initial training data.

The relentless march of model scaling, exemplified by DeepSeek-V3.2, feels less like innovation and more like rearranging the deck chairs on the Titanic. This pursuit of ever-larger models, coupled with intricate training regimens like reinforcement learning for agentic tasks, simply creates more complex systems prone to unpredictable failure. As Andrey Kolmogorov observed, “The most important things are always the simplest.” Yet, here we are, building baroque architectures of attention mechanisms and hoping for elegance. One anticipates production will swiftly demonstrate that even the most meticulously crafted sparse attention will eventually succumb to a cleverly crafted prompt-or just a random input. It’s a beautiful illusion, until it isn’t.
What’s Next?
The pursuit of ever-larger language models, exemplified by DeepSeek-V3.2, inevitably leads to diminishing returns. Each iteration refines attention mechanisms and training procedures, yet the fundamental problem remains: these models are still, at their core, sophisticated pattern-matching engines. The current focus on scaling and reinforcement learning for ‘agentic tasks’ feels suspiciously like applying more power to a fundamentally brittle system. Production environments will undoubtedly reveal corner cases, biases, and unexpected failures that no amount of pre-training can fully anticipate. The model’s performance, while impressive on benchmarks, will be quickly eroded by the realities of messy, real-world data.
The inevitable next step isn’t simply more parameters, but a reckoning with the inherent limitations of this approach. Research will likely shift – or be forced to shift – toward techniques that prioritize robustness, interpretability, and efficient resource utilization. The emphasis on long-context handling is a tacit admission that current architectures struggle with maintaining coherence, and the solutions proposed are, predictably, computationally expensive.
If this paper represents a peak, it will be a peak of elegant complexity, soon buried under the weight of technical debt. The history of machine learning is littered with ‘revolutionary’ architectures that ultimately proved unsustainable. It’s a good model, undoubtedly. But if code looks perfect, no one has deployed it yet.
Original article: https://arxiv.org/pdf/2512.02556.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Silver Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 20 Films Where Black Directors Subverted Hollywood’s White Savior Tropes
2025-12-03 17:20