Author: Denis Avetisyan
New research explores whether large language models can move beyond simple fact-checking to identify the specific evidence supporting or refuting a statement.

This study introduces a novel dataset for fine-grained evidence extraction in Czech and Slovak, assessing the performance of various large language models and observing diminishing returns with scale.
Despite advances in natural language processing, reliably grounding fact-checks in precise textual evidence remains a significant challenge. This paper, ‘Can LLMs extract human-like fine-grained evidence for evidence-based fact-checking?’, introduces a new Czech and Slovak language dataset for evaluating the capacity of large language models to perform fine-grained evidence extraction-identifying the exact spans of text supporting or refuting a claim. Analysis reveals diminishing returns in performance as model size increases, with the 8 billion parameter llama3.1 model achieving competitive results despite its relatively small footprint. Could a focus on architectural efficiency, rather than sheer scale, be key to building LLMs that excel at evidence-based reasoning?
The Echo of Ground Truth: Mapping Evidence in Morphological Space
The true potential of large language models (LLMs) in tasks like evidence-based reasoning remains largely unexplored for languages beyond English, particularly those with complex grammatical structures and limited digital resources. Evaluating an LLM’s capacity to accurately pinpoint supporting evidence isn’t simply a matter of keyword matching; it demands datasets meticulously annotated to capture nuanced relationships between claims and proof. Morphologically rich languages-where words change significantly to convey grammatical meaning-present a unique challenge, requiring annotations that account for these variations. Consequently, the development of robust, high-quality datasets for these lower-resource languages is not merely desirable, but essential to genuinely assess and improve LLM performance in understanding and utilizing information across a wider range of linguistic contexts.
A significant challenge in evaluating large language models (LLMs) lies in assessing their ability to truly understand and extract supporting evidence, rather than simply identifying keyword matches. To address this, researchers have created a novel Czech/Slovak dataset characterized by its detailed, fine-grained annotations. Unlike datasets relying on broad span selection, this resource pinpoints specific textual units that directly support a given claim, demanding a more nuanced comprehension from LLMs. These precise annotations move beyond superficial keyword overlap, allowing for a more rigorous evaluation of a model’s reasoning capabilities and its ability to synthesize information – a critical step towards building genuinely intelligent systems capable of handling the complexities of morphologically rich, and often under-represented, languages.
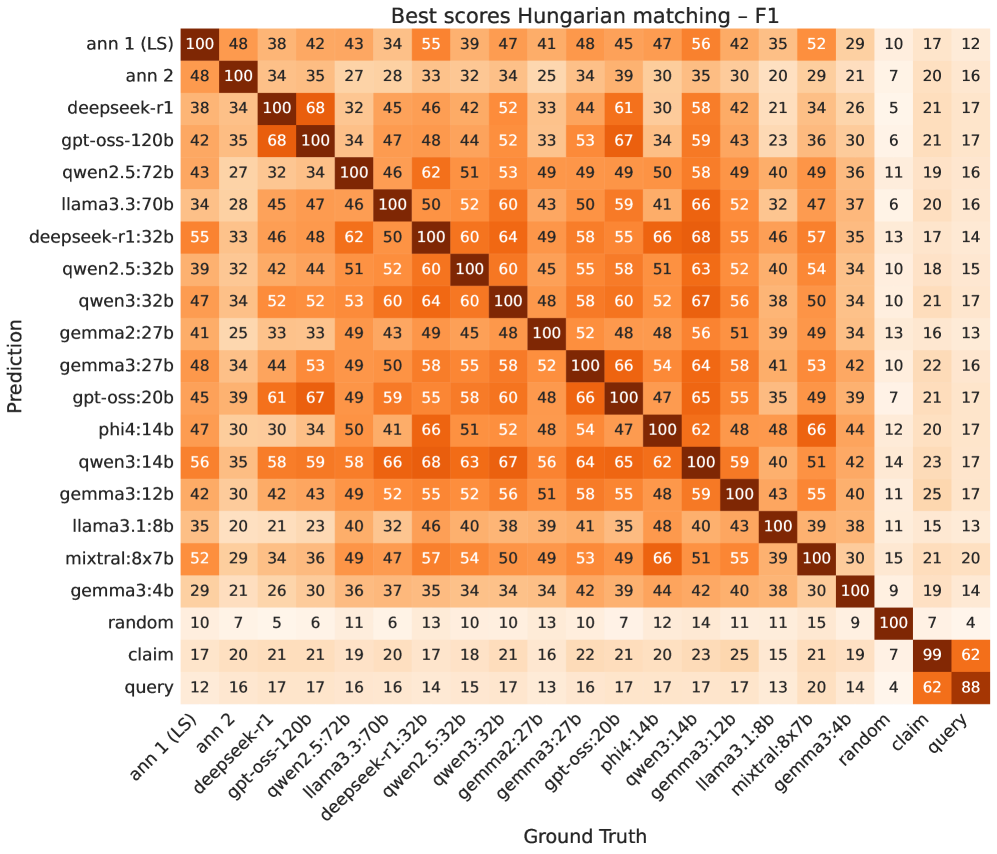
Establishing the validity of any dataset used to evaluate artificial intelligence models demands a careful assessment of how consistently different human annotators interpret and label the information. In the creation of this Czech/Slovak dataset, inter-annotator agreement was rigorously measured using a Token-level F1 score, resulting in a value of 47. This metric indicates a substantial degree of consensus among the annotators, signifying that the labels assigned to the data are not arbitrary but reflect a shared understanding of the evidence being identified. Such a score assures researchers that the dataset provides a stable and dependable ‘ground truth’ against which to benchmark the performance of language models, fostering confidence in the evaluation process and facilitating meaningful progress in fine-grained evidence extraction.
The newly created Czech/Slovak dataset is poised to become a cornerstone for evaluating and improving large language models (LLMs) in the nuanced task of evidence extraction. Existing benchmarks often fall short when assessing a model’s ability to pinpoint precise supporting text, relying instead on simpler metrics like keyword matching. This dataset, however, facilitates a far more granular assessment, demanding that LLMs demonstrate a true understanding of context and meaning to accurately identify relevant evidence. By providing a robust and consistently annotated resource, it enables researchers to move beyond superficial evaluations and drive genuine progress in the field of fine-grained information retrieval, particularly for languages with complex morphological structures and limited digital resources. The availability of such a benchmark is expected to accelerate development and allow for more meaningful comparisons between different LLM architectures and training strategies.
Unveiling the Algorithm: LLMs as Evidence Cartographers
Large Language Models (LLMs) present a novel methodology for automated evidence extraction, moving beyond traditional keyword-based information retrieval. Given a specific claim, these models can analyze textual data to pinpoint and isolate relevant evidence spans – the precise portions of text that support or refute the claim. This capability stems from the LLM’s inherent capacity for contextual understanding and semantic reasoning, allowing it to assess the relationship between the claim and the surrounding text, rather than simply identifying overlapping keywords. The process involves inputting both the claim and the text into the LLM, which then generates or identifies the most relevant textual segments as supporting evidence. This approach promises increased accuracy and efficiency in tasks requiring evidence-based reasoning and decision-making.
Current research is investigating the application of Large Language Models (LLMs), specifically DeepSeek-R1, Qwen3, and GPT-OSS, to the task of evidence extraction. These models demonstrate an ability to process and understand textual context, which is critical for identifying relevant supporting evidence for a given claim. Unlike traditional keyword-based methods, these LLMs utilize their generative capabilities to not simply locate potential evidence, but to interpret the text and determine if it logically supports the claim, enabling a more nuanced approach to information retrieval. The models are being evaluated based on their ability to generate evidence spans that align with human annotations, leveraging metrics such as token-level F1 scores to quantify performance.
While Large Language Models (LLMs) demonstrate potential for evidence extraction, direct application often yields suboptimal results. Constrained decoding techniques address this by guiding the LLM’s generation process to adhere to specific criteria, such as requiring extracted spans to directly support the claim or limiting output to factual statements present in the source text. These constraints mitigate the LLM’s tendency to hallucinate or generate irrelevant content, thereby improving the precision and relevance of extracted evidence. Specifically, constrained decoding methods can enforce lexical overlap between the generated evidence and the claim, or utilize knowledge graphs to verify the factual consistency of the extracted spans, leading to substantial gains in evaluation metrics like token-level F1 score.
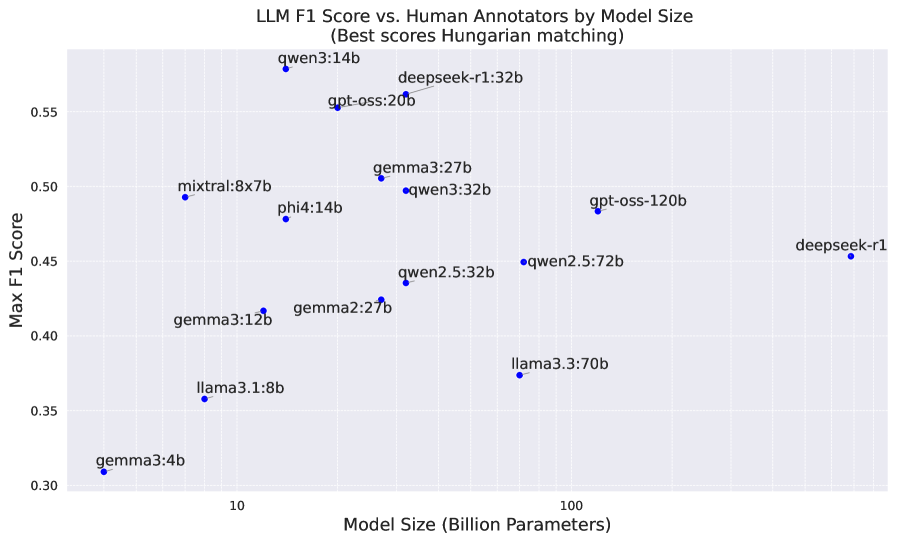
Current evidence extraction methodologies are evolving beyond traditional information retrieval, which relies heavily on keyword matching and statistical relevance. Recent advancements utilize Large Language Models (LLMs) such as the 14B Qwen3, 32B DeepSeek-R1, and 20B GPT-OSS to achieve a more semantic understanding of evidence. Evaluations demonstrate these models can attain a token-level F1 score of up to 56 when compared against human annotations, indicating a substantial improvement in identifying relevant text spans based on contextual meaning rather than superficial features. This shift allows for the extraction of evidence even when paraphrased or expressed implicitly, a capability generally absent in conventional retrieval systems.
The Ghosts in the Machine: Establishing a Baseline of Expectation
Establishing a performance floor for Large Language Model (LLM) evaluation necessitates comparison against non-neural baselines. These baselines – including Random Baseline, which outputs tokens randomly; Claim Baseline, which simply restates the input claim; and Query Baseline, which returns the original query – represent the lowest achievable performance. By benchmarking against these methods, researchers can determine if an LLM demonstrates genuine understanding and reasoning capabilities, or if its performance is merely attributable to chance or trivial pattern matching. These baselines provide a crucial point of reference, allowing for a quantifiable assessment of the value added by the neural network architecture and training data.
The Hungarian Matching Algorithm addresses the challenge of aligning predicted tokens with ground truth annotations when calculating token-level F1 scores. Unlike simple exact match comparisons, this algorithm optimally assigns each predicted token to a single ground truth token, and vice versa, minimizing the overall mismatch cost. This is crucial because LLM outputs and human annotations rarely exhibit a one-to-one correspondence due to paraphrasing or differing phrasing. By finding the best possible alignment, the Hungarian algorithm ensures a more accurate and fair evaluation of precision and recall, as it avoids penalizing correct but differently worded responses. The algorithm guarantees an optimal, cost-minimizing matching, which is essential for reliable comparison across different LLMs and against human performance, especially when dealing with variable-length sequences and non-exact matches.
The token-level F1 score provides a granular evaluation of information extraction and text generation systems by measuring the overlap between predicted tokens and those present in the ground truth annotation. Calculated as the harmonic mean of precision and recall – precision representing the proportion of predicted tokens that are correct, and recall representing the proportion of ground truth tokens that are correctly predicted – the F1 score offers a balanced assessment. Specifically, $F1 = 2 (Precision Recall) / (Precision + Recall)$. A higher token-level F1 score indicates a greater degree of overlap and, consequently, better performance in accurately identifying and extracting relevant information, enabling a detailed comparison of different methods at the individual token level.
Rigorous benchmarking of evaluated Large Language Models (LLMs) reveals varying performance levels when assessing error rates. Specifically, the mixtral:8x7b model demonstrated an error rate of 61.8% on the tested datasets. In contrast, the qwen2.5:72b model achieved the lowest observed error rate among the evaluated models. These quantitative results provide a baseline for comparative analysis and directly inform subsequent development efforts, guiding optimization strategies and resource allocation to improve overall model accuracy and reliability.
The Looming Horizon: Implications for a Trustworthy AI
The ability to accurately extract relevant evidence from text holds transformative potential for a range of critical applications. Fact verification systems, for instance, rely on identifying supporting or refuting evidence to assess the veracity of claims, while question answering benefits from pinpointing precise textual passages that provide answers. Perhaps most significantly, legal reasoning – a domain demanding meticulous analysis and justification – can be greatly enhanced through automated evidence retrieval, assisting in case law research and the construction of legal arguments. This capability extends beyond simply locating keywords; it requires a nuanced understanding of semantic relationships and the ability to discern evidence that implicitly supports or contradicts a given assertion, ultimately paving the way for more reliable and trustworthy artificial intelligence systems in domains where accuracy is paramount.
A newly created dataset and accompanying evaluation framework offer a significant boon to natural language processing research focused on low-resource languages, specifically Czech and Slovak. These languages often lack the extensive digital resources available for languages like English or Mandarin, hindering the development of robust AI models. This resource addresses this gap by providing a curated collection of claims and evidence, enabling researchers to rigorously test and refine methods for tasks such as fact verification and evidence-based reasoning. The availability of this benchmark promotes comparative analysis of different approaches and accelerates progress in building AI systems that can effectively process and understand information in under-represented languages, ultimately broadening the reach and inclusivity of artificial intelligence technologies.
Further research endeavors are increasingly directed toward bolstering the resilience and adaptability of Large Language Models (LLMs) when confronted with intricate and subtly expressed assertions. Current LLM-based methods often struggle with claims requiring deep contextual understanding or those containing implicit assumptions, highlighting a critical need for improved reasoning capabilities. Investigations are focusing on techniques like incorporating knowledge graphs, refining training data with adversarial examples, and developing more sophisticated attention mechanisms to enable LLMs to discern nuance and avoid superficial pattern matching. Success in these areas will not only enhance the accuracy of evidence extraction but also pave the way for more trustworthy AI systems capable of handling the ambiguities inherent in natural language and making sound judgments based on complex information.
The ongoing refinement of evidence extraction techniques holds the potential to fundamentally reshape the landscape of artificial intelligence, moving beyond simple task completion towards systems characterized by genuine reliability and trustworthiness. As these methods mature, applications will not merely process information, but will be able to demonstrably justify their conclusions with supporting evidence. This shift is crucial for sensitive domains like legal reasoning, medical diagnosis, and financial analysis, where accountability and transparency are paramount. The development of AI capable of explaining its reasoning fosters greater user confidence and facilitates effective human-machine collaboration, ultimately paving the way for more responsible and beneficial integration of artificial intelligence into everyday life.
The study meticulously charts the diminishing returns of scale in large language models applied to fine-grained evidence extraction. It’s a predictable trajectory; each added parameter doesn’t solve the problem of nuanced understanding, merely delays the inevitable decay of performance on complex tasks. As Bertrand Russell observed, “The difficulty lies not so much in developing new ideas as in escaping from old ones.” This applies perfectly to the relentless pursuit of larger models as a panacea. The research demonstrates that simply increasing size doesn’t overcome the fundamental limitations of these systems when confronted with the subtleties of human language, particularly in lower-resource languages like Czech and Slovak. The focus, therefore, shifts from brute force to architectural innovation – a recognition that systems aren’t built, they evolve, and entropy is an inescapable constant.
The Shape of Things to Come
The pursuit of ‘fine-grained evidence’ is less about conquering falsehood and more about mapping the inevitable fractures within any claim. This work, documenting performance on Czech and Slovak datasets, reveals a familiar pattern: diminishing returns with increasing model scale. It isn’t a ceiling of capability, but a symptom of a deeper truth – systems don’t fail to extract evidence, they evolve to reflect the inherent ambiguity of language itself. Long stability on these benchmarks will not signify success, but will mask the emergence of unforeseen blind spots.
The focus now must shift from chasing ever-larger models to understanding the ecology of evidence. What forms of reasoning are truly resistant to manipulation? What signals, beyond simple textual overlap, denote genuine support? The datasets themselves, carefully annotated as they are, represent a snapshot, a momentary equilibrium. The real challenge lies in anticipating how claims – and the evidence supporting them – will mutate over time.
One suspects that the ultimate system won’t ‘check facts’ at all. It will chart the topography of belief, identifying not truth, but the points of greatest instability – the places where narratives are most susceptible to change. The goal isn’t to build a fortress against falsehood, but to cultivate a garden where both truth and error can flourish, revealing their complex interdependencies.
Original article: https://arxiv.org/pdf/2511.21401.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Brent Oil Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Games That Faced Bans in Countries Over Political Themes
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2025-11-30 10:08