Author: Denis Avetisyan
Researchers have developed a novel system that focuses on the subtle frequency characteristics of audio to reliably identify artificially generated speech.
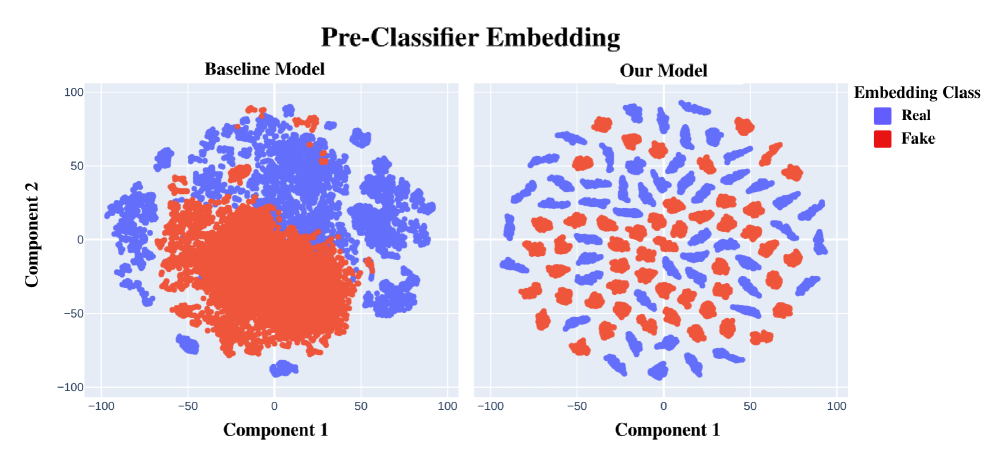
SONAR leverages spectral-contrastive learning and a dual-path framework to model high-frequency residuals and address spectral bias in deepfake audio.
Despite advances in deepfake detection, current audio forensics struggle to generalize to unseen data due to inherent spectral bias in neural networks. To address this, we introduce SONAR: Spectral-Contrastive Audio Residuals for Generalizable Deepfake Detection, a novel framework that explicitly disentangles audio into low- and high-frequency representations via a dual-path architecture. By elevating faint high-frequency residuals as crucial learning signals and employing a frequency-aware contrastive loss, SONAR achieves state-of-the-art performance and faster convergence on standard benchmarks. Could this frequency-guided approach unlock more robust and adaptable deepfake detection across diverse audio modalities and signal types?
The Erosion of Trust: Confronting the Rise of Synthetic Audio
The rapid evolution of generative artificial intelligence is now capable of producing audio deepfakes with astonishing fidelity, blurring the lines between authentic and fabricated sound. These synthetic creations, generated through techniques like voice cloning and speech synthesis, are becoming increasingly difficult for humans – and even sophisticated algorithms – to discern from genuine recordings. This poses a substantial threat to security, as convincingly impersonated voices can be used for fraudulent activities, social engineering attacks, and the spread of disinformation. The erosion of trust in audio evidence has far-reaching implications for legal proceedings, journalism, and everyday digital interactions, demanding innovative solutions to verify the provenance and authenticity of sound in an increasingly synthetic world.
Conventional deepfake detection techniques, often reliant on identifying specific artifacts or inconsistencies introduced during the synthesis process, are increasingly challenged by the sophistication of modern generative models. These methods frequently falter when confronted with deepfakes exhibiting high fidelity and diverse characteristics, particularly those created using techniques like diffusion models or generative adversarial networks (GANs) trained on expansive datasets. The variability in synthesis approaches – differing algorithms, training data, and post-processing techniques – produces a wide spectrum of deepfake ‘signatures’, making it difficult to establish universal detection criteria. Furthermore, real-world deployments introduce additional complexities such as compression, noise, and variations in recording conditions, effectively masking the subtle cues that laboratory-based detectors depend upon and diminishing their overall effectiveness. This struggle highlights the need for more robust and adaptable detection strategies capable of generalizing across diverse deepfake types and environmental conditions.
The escalating challenge of deepfake detection isn’t simply about improving algorithms; it’s fundamentally linked to the data upon which those algorithms are trained. Most research historically relied on synthetic media generated within carefully controlled laboratory settings – pristine audio and video created to test detection methods. However, the vast majority of deepfakes encountered in real-world scenarios – termed ‘in-the-wild’ data – are far more complex. These recordings often exhibit significant noise, compression artifacts, varying recording qualities, and are frequently altered after initial synthesis. This introduces substantial variability that drastically reduces the effectiveness of detection systems trained on clean, synthetic examples, requiring a shift towards robust methods capable of generalizing across a diverse range of realistic conditions and accounting for post-processing manipulations.
The preservation of trust in digital communication hinges upon the development of robust deepfake detection technologies. As synthetic media becomes increasingly sophisticated, the potential for malicious use – ranging from disinformation campaigns and reputational damage to financial fraud and political manipulation – escalates dramatically. Without reliable methods to distinguish between authentic content and fabricated realities, the very foundations of online information become vulnerable, eroding public confidence and potentially destabilizing societal structures. Consequently, prioritizing effective detection isn’t merely a technical challenge; it represents a critical imperative for safeguarding the integrity of information ecosystems and protecting individuals and institutions from the harms of deceptive media.

SONAR: A Dual-Path Framework for Discerning Authenticity
SONAR employs a Dual-Path Framework designed for the concurrent analysis of audio content and its associated noise characteristics. This architecture deviates from single-stream approaches by processing these two components in parallel, enabling the model to capture subtle discrepancies often present in manipulated audio. The framework receives both the raw audio signal and a representation of its inherent noise profile as independent inputs. These inputs are then processed through separate, yet interconnected, pathways within the network, allowing for a comparative assessment of content integrity and noise consistency. This parallel processing is intended to improve detection accuracy and robustness against various audio manipulation techniques by providing a more comprehensive analysis than traditional methods.
Spectral Residual Modulation (SRM) filters are a key component of the SONAR framework, employed to isolate high-frequency residuals present in audio signals. These residuals, derived from the difference between the original signal and its spectral reconstruction, are particularly sensitive to alterations introduced during audio manipulation or synthesis. The process involves modulating the spectral residuals to emphasize subtle artifacts often introduced by deepfake techniques, which may not be readily apparent in the core audio content. By focusing on these high-frequency components – typically above $8$ kHz – the SRM filters provide a refined signal for detecting inconsistencies and anomalies indicative of artificial audio.
Frequency-Contrastive Learning (FCL) within the SONAR framework operates by training a model to maximize the distance between feature embeddings of genuine and synthesized audio signals in the frequency domain. This is achieved through a contrastive loss function that encourages similar embeddings for different segments of authentic audio and dissimilar embeddings for authentic versus deepfake audio. Specifically, FCL leverages paired positive and negative examples during training; positive pairs consist of different segments from the same genuine audio source, while negative pairs consist of genuine audio segments matched with synthesized or manipulated audio. By optimizing this contrastive objective, the model learns to create discriminative feature representations that effectively highlight the spectral discrepancies between natural and artificial audio, thereby improving the framework’s ability to detect audio deepfakes.
Content-Noise Alignment within the SONAR framework operates on the principle that genuine audio exhibits a consistent relationship between its content-bearing components and background noise characteristics. Deepfake audio, conversely, frequently displays misalignment due to the artificial synthesis or splicing processes used in their creation. SONAR analyzes spectral features to quantify this alignment; inconsistencies, such as noise patterns that do not correlate with the acoustic environment implied by the content, or abrupt shifts in noise profiles, are flagged as potential indicators of manipulation. This alignment is assessed across multiple frequency bands to improve robustness and detect subtle inconsistencies that might be missed by single-band analysis, providing a key discriminant between authentic and synthesized audio.
Refining Detection: Advanced Representations and Loss Functions
SONAR leverages the XLSR model, a self-supervised learning approach trained on approximately 6,000 hours of multilingual speech data, to generate robust acoustic feature embeddings. XLSR utilizes a Transformer architecture and is pre-trained with objectives including masked prediction of speech features and discrimination between different speakers and languages. This pre-training enables SONAR to effectively capture nuanced acoustic characteristics relevant to spoofing detection, even in the presence of variations in accent, language, and recording conditions. The resulting feature representations serve as input to subsequent layers for classification, providing a strong foundation for accurate anti-spoofing performance.
AASIST, the Audio Anti-Spoofing System, serves as a core component of SONAR’s architecture, leveraging its pre-trained capabilities to establish a robust baseline for detecting spoofed audio. Originally developed as a standalone system for presentation attack detection, AASIST utilizes a deep neural network trained on a large and diverse dataset of real and synthetic speech samples. Integrating AASIST into SONAR allows for immediate utilization of its existing feature extraction and classification mechanisms, thereby accelerating development and improving initial performance metrics. Subsequent enhancements within SONAR build upon this foundation, refining the anti-spoofing capabilities through advanced representations and loss functions, while retaining the core strengths of AASIST’s established detection protocols.
The Jensen-Shannon Divergence (JSD) Loss function is implemented to optimize the feature embeddings generated by the system, specifically targeting the discrimination between genuine and spoofed audio. JSD measures the similarity between two probability distributions, and in this context, is applied to the latent space representations of real and fake audio pairs. The loss function minimizes the JSD between real content and corresponding noise, effectively drawing these embeddings closer together. Conversely, it maximizes the JSD between real content and spoofed audio, pushing their embeddings further apart. This approach facilitates a more robust and discriminative feature space, improving the system’s ability to accurately classify audio as genuine or spoofed. The $JSD(P||Q) = \frac{1}{2}D_{KL}(P||\frac{P+Q}{2}) + \frac{1}{2}D_{KL}(Q||\frac{P+Q}{2})$ formulation ensures a symmetric and finite divergence even when distributions have no overlap.
SONAR’s implementation prioritizes frequency-domain analysis to mitigate the vulnerabilities present in time-domain approaches. Traditional methods can be negatively impacted by low-frequency masking, where strong low-frequency components obscure subtle, yet important, spoofing artifacts. Furthermore, spectral bias, a tendency to favor certain spectral characteristics, can lead to inaccurate classifications. By operating directly on the frequency spectrum, SONAR reduces reliance on absolute amplitude values, allowing for a more robust detection of spectral distortions indicative of manipulation, regardless of overall signal strength or low-frequency dominance. This approach enhances the system’s resilience to common audio processing techniques used in spoofing attacks and improves generalization across diverse acoustic environments.

Demonstrating Impact: Performance and Future Directions
Evaluations reveal that the SONAR framework demonstrates strong performance in deepfake detection, achieving an Equal Error Rate (EER) of 1.45% when tested against the DF dataset and 5.43% on the more challenging In-the-Wild dataset. This metric, representing the point where false acceptance and false rejection rates are equal, signifies a high level of accuracy in distinguishing between authentic and manipulated content. The low EER scores indicate that SONAR minimizes both incorrectly identifying real footage as fake and vice versa, highlighting its effectiveness across different data distributions and levels of manipulation. These results position SONAR as a competitive solution within the evolving landscape of deepfake detection technologies, capable of maintaining precision even with increasingly sophisticated forgeries.
The SONAR framework demonstrates notable resilience when confronted with diverse and challenging attack scenarios commonly used to evade deepfake detection systems. Crucially, this robustness extends to ‘In-the-Wild’ data – real-world videos sourced from the internet which inherently possess greater variability in lighting, pose, and compression artifacts compared to controlled laboratory settings. This ability to maintain high accuracy with such complex data suggests a significant advancement over existing methods, which often struggle with the nuances of authentic video content. The framework’s performance isn’t simply about achieving a low error rate on curated datasets; it indicates a capacity to generalize effectively and reliably identify manipulated content even amidst the imperfections and distortions present in everyday videos, representing a critical step towards practical deployment in real-world scenarios.
The efficiency of the SONAR framework in deepfake detection is markedly improved through accelerated convergence; the system achieves performance comparable to existing methods in a fraction of the training time. While conventional deepfake detection models often require approximately 100 training epochs to reach optimal accuracy, SONAR demonstrably achieves comparable results within just 4 to 6 epochs. This significant reduction in training duration not only conserves computational resources but also facilitates more rapid adaptation to emerging deepfake techniques and datasets, offering a practical advantage in the ongoing arms race against increasingly realistic synthetic media. The ability to quickly learn and generalize from limited data represents a crucial step toward real-time, scalable deepfake detection systems.
The SONAR framework achieves notable performance gains in deepfake detection without sacrificing computational efficiency. While enhancing accuracy across benchmark datasets, the system introduces a minimal increase in inference time – only 15 to 25 percent – when compared to a single-stream XLSR baseline. This represents a critical advantage, as many real-world applications demand both high detection rates and rapid processing speeds; a substantial increase in computational cost often hinders practical deployment. The relatively small overhead associated with SONAR suggests it can be effectively integrated into existing systems with minimal disruption, making advanced, frequency-domain analysis a viable solution for combating increasingly sophisticated manipulated media.
The escalating realism of deepfakes demands a shift in detection strategies, and this research demonstrates the critical role of analyzing content within the frequency domain. Traditional methods often focus on pixel-level discrepancies, but subtle manipulations become increasingly difficult to discern. Instead, this work successfully leverages frequency analysis to expose inconsistencies introduced during the deepfake creation process – alterations that may be imperceptible in the spatial domain. Crucially, the framework also emphasizes content-noise alignment, recognizing that deepfakes often exhibit a mismatch between the natural noise patterns of authentic content and the artificial noise generated during synthesis. By prioritizing these two elements – frequency characteristics and noise consistency – the approach proves remarkably effective in identifying even highly sophisticated forgeries, offering a promising pathway toward more robust and reliable deepfake detection systems.
Continued development of the SONAR framework prioritizes a move towards holistic deepfake detection by integrating both audio and video streams, recognizing that deceptive content often manipulates multiple sensory inputs. This expansion into multimodal analysis aims to leverage the complementary information present in different data types, potentially exposing inconsistencies undetectable in single-stream approaches. Crucially, researchers intend to implement adaptive learning strategies, enabling SONAR to dynamically adjust to the ever-changing landscape of deepfake technology. These strategies will allow the system to continuously refine its detection capabilities, addressing new attack vectors and increasingly sophisticated forgeries without requiring extensive retraining or manual intervention, thereby ensuring long-term efficacy against evolving threats.
The architecture detailed in this work, SONAR, embodies a holistic approach to deepfake detection. It doesn’t simply isolate anomalies but considers the interplay between spectral components-low and high frequencies-within audio. This resonates deeply with the observation of John von Neumann: “It is impossible to be precise about anything.” The system’s dual-path framework, explicitly modeling these relationships, acknowledges the inherent complexity and imprecision within the data itself. By embracing a contrastive learning approach and focusing on frequency-guided representation, SONAR demonstrates that scalability arises from clear, interconnected ideas, not simply computational power. The system’s strength lies in understanding the whole, rather than attempting to ‘fix’ isolated parts.
Future Directions
The introduction of SONAR’s dual-path framework, explicitly modeling relationships between spectral components, suggests a broader principle: effective signal analysis often resides not in isolating features, but in understanding their interactions. The system’s performance, while notable, implicitly acknowledges a continuing limitation: current deepfake detection remains largely reactive. It identifies artifacts of generation, rather than fundamental inconsistencies in signal structure. A more robust approach may necessitate a shift toward modeling what constitutes authentic signal coherence, rather than merely detecting deviation.
Furthermore, the emphasis on high-frequency residuals, while currently effective, invites speculation. Such reliance on specific artifacts seems inherently brittle. Future work should investigate the generalizability of this approach across different codecs, recording conditions, and, crucially, evolving generative models. Documentation captures structure, but behavior emerges through interaction; a system that anticipates how deepfakes will change, rather than simply reacting to current iterations, represents a more enduring solution.
Ultimately, the field confronts a meta-problem: the accelerating arms race between detection and generation. The pursuit of increasingly sophisticated artifacts threatens to overshadow the underlying principle of signal integrity. A fruitful direction may lie in abandoning the frame-by-frame assessment of authenticity, and instead focusing on the statistical consistency of a signal over time-a holistic view where subtle structural anomalies, rather than overt artifacts, reveal the deception.
Original article: https://arxiv.org/pdf/2511.21325.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Brent Oil Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Games That Faced Bans in Countries Over Political Themes
2025-11-29 00:38