Author: Denis Avetisyan
New research explores how reinforcement learning can optimize the reasoning process in large language models, leading to more efficient and effective problem-solving.
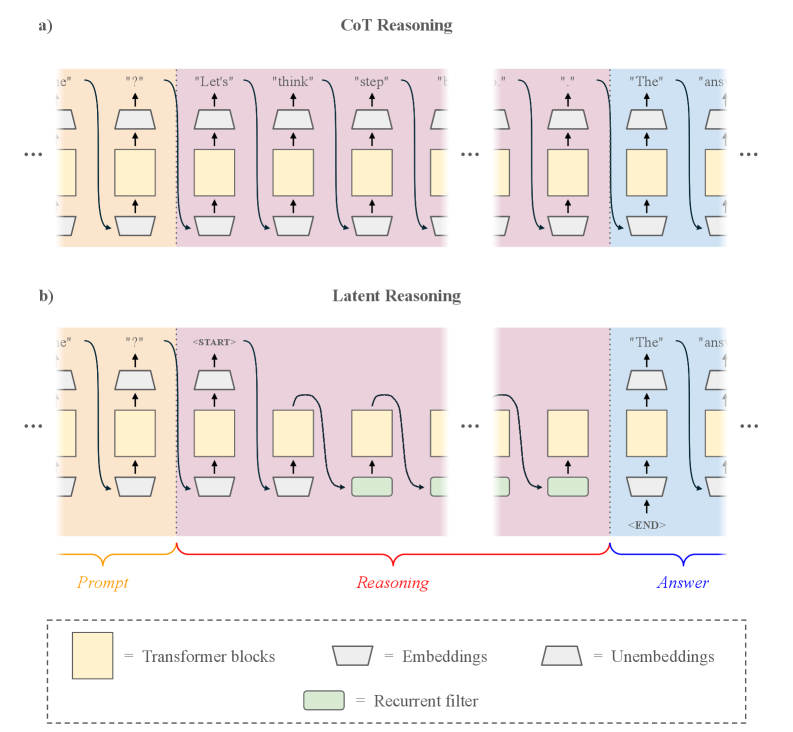
This work introduces a method for adaptive latent reasoning, allowing models to dynamically adjust their reasoning length through knowledge distillation and reinforcement learning.
While large language models excel at complex reasoning, their reliance on lengthy, token-based chains-of-thought can be computationally expensive. This work, ‘Learning When to Stop: Adaptive Latent Reasoning via Reinforcement Learning’, introduces a reinforcement learning methodology to optimize latent reasoning-a technique compressing reasoning steps beyond human language-by adaptively determining optimal reasoning length. Experiments demonstrate a significant 52% reduction in reasoning length without sacrificing accuracy, offering a pathway to more efficient and scalable models. Could this adaptive approach unlock even greater compressive capabilities and broaden the applicability of latent reasoning across diverse language tasks?
Beyond Explicit Thought: The Limits of Verbose Reasoning
Chain-of-Thought reasoning, a technique that encourages large language models to articulate their reasoning steps, has undeniably pushed the boundaries of AI problem-solving. However, this approach isn’t without significant drawbacks. The very nature of explicitly detailing each step-while beneficial for interpretability-results in substantially longer outputs compared to direct answer generation. This increased length translates directly into higher computational costs, both during training and inference, demanding more processing power and time. As models scale and tackle increasingly complex challenges, the exponential growth in these costs poses a practical limitation, hindering the deployment of these powerful systems and prompting researchers to explore more efficient alternatives that can achieve comparable reasoning abilities with a reduced footprint.
Attempts to enhance reasoning in large language models through simply increasing the scale of Chain-of-Thought prompting and similar techniques are increasingly running into the law of diminishing returns. While initially effective, the computational cost and length of these reasoning chains grow disproportionately to any gains in accuracy, creating a practical barrier to solving truly complex problems. This suggests that future progress hinges not on brute-force scaling, but on developing fundamentally more efficient reasoning architectures – systems capable of achieving deeper understanding and more concise inferences. Researchers are therefore exploring alternative approaches that prioritize reasoning efficiency, potentially through mechanisms inspired by human cognitive shortcuts or by leveraging more compact representations of knowledge, to overcome the limitations of current, increasingly unwieldy methods.
Despite advances in artificial intelligence, current reasoning methods often falter when confronted with problems demanding more than simple logical steps. These limitations become apparent in scenarios requiring contextual understanding, common sense, or the ability to navigate ambiguity-qualities essential for genuine intelligence. While models excel at tasks with clear-cut solutions, they struggle with the subtleties of real-world challenges where information is incomplete or contradictory. This inability to perform deep and nuanced reasoning isn’t merely a technical hurdle; it represents a fundamental barrier to achieving true artificial general intelligence, hindering the development of systems capable of flexible, adaptive problem-solving and preventing them from moving beyond pattern recognition to genuine understanding. The core issue isn’t processing power, but rather the architecture’s inability to effectively synthesize information and draw inferences in a manner comparable to human cognition.

Latent Reasoning: Efficiency Through Implicit Thought
Latent Reasoning operates by directly utilizing the hidden states within a Transformer architecture, circumventing the conventional method of generating explicit, multi-step reasoning traces. Rather than producing a sequence of intermediate thoughts for each problem, the system performs computations entirely within the model’s internal representational space. This is achieved by extracting and manipulating these hidden states, allowing the model to arrive at a solution without the need for externalized, token-based reasoning steps. Consequently, the observable output represents the final answer derived from this implicit internal process, effectively compressing the reasoning pathway into the model’s existing parameters and activations.
Latent Reasoning achieves efficiency by processing information directly within the Transformer model’s hidden states, circumventing the need for extensive token generation typically associated with intermediate reasoning steps. This internal operation results in a substantial 52.94% reduction in reasoning tokens compared to traditional methods. Crucially, this reduction in computational load is achieved without compromising the accuracy of the reasoning process, indicating that the model can perform equivalent computations with significantly fewer resources. The decreased token count translates directly to lower computational costs and faster inference speeds, making Latent Reasoning a more scalable approach to complex problem-solving.
Traditional language models execute reasoning through the explicit generation of intermediate reasoning steps, requiring substantial computational resources to produce and process these textual outputs. Latent Reasoning diverges from this approach by shifting the computational locus to the model’s internal hidden states; instead of generating a traceable series of steps, the reasoning process is performed as implicit computation within the Transformer network. This internal operation directly leverages the existing learned representations, effectively bypassing the need for externalized, token-based reasoning and resulting in a more efficient and condensed reasoning pathway.

Refining Implicit Thought: Optimizing Latent Reasoning
Supervised fine-tuning establishes a baseline level of competence in latent reasoning tasks by training the model on labeled examples; however, performance plateaus due to limitations in exposure to diverse reasoning paths and optimization of the internal reasoning process itself. While fine-tuning imparts initial knowledge, it does not inherently optimize for efficiency or robustness against complex or ambiguous inputs. Subsequent refinement through techniques like reinforcement learning and targeted penalty mechanisms are therefore necessary to surpass the limitations of supervised learning and achieve substantial gains in both accuracy and computational cost.
Reinforcement learning is utilized to directly optimize the internal reasoning process of latent models, moving beyond the limitations of supervised fine-tuning. Algorithms such as Group Relative Policy Optimization (GRPO) are employed to shape the model’s decision-making during reasoning steps, rewarding sequences that lead to accurate conclusions and penalizing unproductive or circular logic. GRPO specifically addresses challenges in multi-agent reinforcement learning by optimizing policies relative to groups of agents, which translates to improved stability and efficiency when applied to the sequential steps of a reasoning process. This approach allows for fine-grained control over the model’s internal “thought process,” leading to enhanced performance on complex reasoning tasks.
Implementation of length penalties and the THINKPRUNE technique demonstrably improves the efficiency of latent reasoning processes. These methods function by actively discouraging the model from generating excessively long reasoning chains. Experimental results indicate a substantial reduction in reasoning token usage – specifically, a 70.58% decrease – while simultaneously achieving a 0.38% increase in overall accuracy. This optimization suggests that concise reasoning sequences, facilitated by these techniques, can lead to both computational savings and improved performance in latent reasoning tasks.

Distilling Expertise: Enhancing Latent Reasoning with Knowledge Transfer
Knowledge distillation presents a powerful technique for compressing complex reasoning abilities into more streamlined models. This process doesn’t involve simply shrinking a large network; instead, it focuses on transferring the knowledge embedded within its reasoning pathways. Methods like Meaned Reasoning Loss and Intermediate Block Loss facilitate this transfer by encouraging the smaller model to not only match the final output of the larger, more capable model, but also to mimic its internal representations at various stages of reasoning. By focusing on these intermediate layers, the smaller model learns to replicate the nuanced thought processes of its larger counterpart, achieving comparable performance with significantly reduced computational demands. This approach effectively allows for the deployment of sophisticated reasoning capabilities on resource-constrained platforms, broadening the applicability of advanced artificial intelligence.
Current advancements in latent reasoning aren’t limited to simple knowledge transfer; techniques like CODI and COCONUT actively refine the distillation process itself. CODI leverages self-distillation, where a model learns from its own improved outputs, iteratively enhancing its reasoning abilities without reliance on external labeled data. Complementarily, COCONUT employs staged curriculum learning, carefully sequencing training examples from easy to difficult to optimize the model’s learning trajectory. This deliberate progression allows the model to build a strong foundation in basic reasoning before tackling more complex problems, ultimately leading to more robust and efficient performance. These methods represent a shift toward more sophisticated distillation strategies, moving beyond simple imitation to active, curriculum-driven learning.
Adaptive Latent Reasoning represents a significant advancement in model efficiency by enabling a dynamic halt to the reasoning process itself. Instead of uniformly applying computation to every problem, the model learns to recognize when sufficient evidence has been gathered to reach a confident conclusion, thereby preventing wasteful calculations. This approach not only streamlines processing but also achieves a test accuracy of 42.6%, coupled with a substantial 52.94% reduction in token usage – a measure of computational cost. This performance positions Adaptive Latent Reasoning as a strong comparative benchmark against methods like CODI, which achieves an accuracy of 43.2%, demonstrating a compelling trade-off between performance and efficiency in complex reasoning tasks.

Towards Scalable Intelligence: Future Directions in Reasoning Systems
The capacity for robust reasoning hinges on effectively managing internal cognitive states, and recent advancements demonstrate that integrating recurrent filters with latent reasoning models significantly enhances this process. By employing these filters, systems can dynamically process and refine internal representations, allowing for a more nuanced and context-aware understanding of information. This approach moves beyond static reasoning by enabling the model to maintain and update a ‘memory’ of its thought process, crucial for tackling complex, multi-step problems. The resulting improvement in state processing translates directly to a higher quality of reasoning, evidenced by increased accuracy and coherence in problem-solving tasks, particularly those requiring temporal understanding or the integration of prior knowledge. This synergy between recurrent filtering and latent reasoning represents a pivotal step towards building artificial intelligence systems capable of more sophisticated and human-like thought.
Latent reasoning models are gaining a new dimension of control through the strategic implementation of special tokens. These tokens, functioning as internal commands, allow for precise manipulation of the reasoning process itself – effectively guiding the model’s thought steps. Researchers are demonstrating that by inserting these tokens, models can be prompted to focus on specific aspects of a problem, explore alternative solution paths, or even verify the consistency of their own inferences. This granular control moves beyond simply providing an input and awaiting an output; it enables a dynamic interplay where the reasoning trajectory is actively shaped, fostering more reliable and explainable artificial intelligence. The potential lies in crafting models that not only solve problems, but also articulate how they arrived at a solution, opening doors to more robust and trustworthy systems.
Future advancements in reasoning systems are increasingly focused on adaptive strategies and knowledge distillation as pathways to improved efficiency and scalability. These techniques aim to move beyond computationally expensive, monolithic models by enabling systems to dynamically adjust their reasoning processes based on input complexity and resource availability. Knowledge distillation, in particular, allows the transfer of expertise from large, complex models to smaller, more efficient ones, preserving performance while significantly reducing computational demands. By intelligently allocating resources and compressing learned knowledge, researchers anticipate creating reasoning systems capable of handling increasingly intricate problems with greater speed and reduced energy consumption, ultimately paving the way for broader real-world applications and deployment on resource-constrained devices.

The pursuit of efficient reasoning, as detailed in the exploration of adaptive latent reasoning, echoes a fundamental tenet of elegant design. The paper’s focus on optimizing reasoning length through reinforcement learning highlights a commitment to parsimony, discarding unnecessary computational steps. This aligns with Robert Tarjan’s observation: “Complexity is vanity. Clarity is mercy.” The work demonstrates that a model needn’t exhaustively explore every possible reasoning path; instead, it can learn to halt when sufficient evidence is gathered, embodying a streamlined approach to problem-solving. This selective approach, reducing compute while maintaining accuracy, is a testament to the power of focused intelligence and a rejection of needless intricacy.
Where Does the Thread Lead?
The demonstrated capacity to modulate reasoning length via reinforcement learning represents, predictably, not an arrival, but a narrowing of the problem. The efficiency gains are demonstrable, yet the underlying premise – that ‘more’ reasoning is always better, even if optimally truncated – remains unchallenged. Future work must address the quality of reasoning abandoned, not merely the quantity reduced. A system that elegantly stops at the correct answer, while discarding irrelevant computation, is preferable to one that exhaustively explores a broader, but ultimately unproductive, space.
Current iterations rely heavily on reward signals derived from final outputs. This introduces a fragility; the system learns to appear correct, not necessarily to be correct. Investigation into intermediate reward structures, perhaps derived from internal model confidence or consistency checks, may yield more robust and interpretable reasoning processes. The pursuit of ‘adaptive’ reasoning must not devolve into a sophisticated form of post-hoc rationalization.
Ultimately, the question is not simply ‘how long should a model reason?’, but ‘what constitutes reasoning?’. This work provides a mechanism for controlling a process; it does not illuminate the process itself. The field now faces the increasingly uncomfortable task of defining, and then evaluating, the cognitive architecture it is so readily replicating. Unnecessary is violence against attention; let future research focus on distillation, not proliferation.
Original article: https://arxiv.org/pdf/2511.21581.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Gold Rate Forecast
- Palantir and Tesla: A Tale of Two Stocks
- TV Shows That Race-Bent Villains and Confused Everyone
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- How to rank up with Tuvalkane – Soulframe
- The 25 Marvel Projects That Race-Bent Characters and Lost Black Fans
2025-11-28 09:28