Author: Denis Avetisyan
New research systematically examines the design choices that consistently improve the accuracy and adaptability of deepfake detection systems.

A comprehensive evaluation reveals optimal data augmentation strategies, training durations, and continual learning techniques for generalized deepfake detection across diverse generative models.
Despite rapid advances in deepfake detection, performance gains often stem from implementation details rather than fundamental architectural choices. This research, presented in ‘Generalized Design Choices for Deepfake Detectors’, systematically investigates the impact of training procedures, input processing, and continual learning strategies on the accuracy and generalization of deepfake detectors. Our findings reveal that specific data augmentation techniques, extended training durations, and replay-based continual learning consistently improve performance across diverse model architectures and enable state-of-the-art results on the AI-GenBench benchmark. How can these architecture-agnostic best practices accelerate the development of robust and adaptable deepfake detection systems for an evolving threat landscape?
The Erosion of Trust in a Visual World
The accelerating development of artificial intelligence has unlocked the capacity to generate increasingly realistic images and videos, a capability that simultaneously presents exciting opportunities and profound challenges to societal trust. This proliferation of AI-generated imagery erodes the foundations of information integrity, as distinguishing between authentic content and sophisticated forgeries becomes increasingly difficult. The potential for malicious actors to disseminate disinformation, manipulate public opinion, and damage reputations is significantly amplified by this technology; fabricated evidence can now be created with relative ease, undermining faith in visual media as a reliable source of truth. Consequently, critical assessment of all digital content is becoming paramount, and a growing need exists for tools and strategies that can effectively combat the spread of AI-generated misinformation and preserve the integrity of the information landscape.
Current forgery detection techniques, largely reliant on identifying statistical inconsistencies or artifacts introduced during image and video creation, are increasingly challenged by the swift advancement of generative models. These models, such as Generative Adversarial Networks (GANs) and diffusion models, are becoming adept at producing synthetic content that closely mimics real-world data, effectively masking the telltale signs previously used for detection. As generative models grow in sophistication, they not only enhance the realism of deepfakes but also learn to anticipate and circumvent existing detection algorithms. This creates a continuous arms race where detectors struggle to keep pace with the ever-improving ability of generative models to create increasingly convincing forgeries, ultimately eroding confidence in the authenticity of digital media.
Current deepfake detection technologies often falter when confronted with novel manipulations not present in their training data, highlighting a critical need for models capable of broad generalization. Simply memorizing known forgery patterns proves insufficient against the continuously evolving landscape of generative AI; instead, robust detection demands an understanding of the underlying fundamental inconsistencies introduced by these manipulations – things like unnatural blinking rates or subtle distortions in facial geometry. Furthermore, these detection systems are vulnerable to adversarial attacks, where malicious actors intentionally craft subtle perturbations to deepfakes specifically designed to evade detection. Therefore, researchers are actively developing techniques, including those leveraging meta-learning and anomaly detection, to build models that not only recognize known deepfake characteristics but also reliably identify manipulations outside their initial training scope, and withstand intentional attempts to fool them – a crucial step in preserving trust in visual information.
Harnessing Pre-trained Vision: A Foundation for Detection
Transfer learning leverages pre-trained vision models – notably ResNet-50 CLIP, ViT-L CLIP, and DINOv2 – as a foundational element for deepfake detection systems. These models were initially trained on extensive datasets like ImageNet and LAION-400M, enabling them to learn generalized image features. Utilizing these pre-trained weights circumvents the need for training a model from scratch, which demands substantial computational resources and large, labeled deepfake datasets. By adapting these models, specifically their convolutional or transformer layers, to the deepfake detection task, developers can achieve higher accuracy with reduced training time and data requirements. The models’ ability to extract meaningful features from images, independent of the specific deepfake technique, contributes to robust performance across various forgery types.
Pre-trained vision models, such as ResNet-50, CLIP, ViT-L, and DINOv2, acquire robust feature representations during training on extensive datasets like ImageNet and LAION-5B. This pre-training process enables the models to learn hierarchical feature detectors capable of identifying edges, textures, and complex objects independent of specific downstream tasks. Consequently, these learned features generalize effectively across diverse image types and content, providing a strong foundation for transfer learning. The models do not simply memorize training examples; instead, they develop a generalized understanding of visual patterns, making them adaptable to new, unseen images and facilitating performance on tasks with limited labeled data.
Fine-tuning pre-trained vision models, such as ResNet-50, CLIP, ViT-L CLIP, and DINOv2, on datasets specifically curated for deepfake detection offers substantial computational benefits and performance gains. Utilizing a pre-trained model as a starting point bypasses the need to learn low-level image features from scratch, drastically reducing the number of trainable parameters and, consequently, the training time required to achieve a given level of accuracy. Initial performance metrics, including precision, recall, and F1-score, are consistently higher when employing fine-tuning versus training a model from random initialization. The transfer of learned representations allows the model to generalize more effectively to unseen deepfake examples, particularly when the deepfake dataset is limited in size or diversity.
Multiclass training strategies for deepfake detection extend beyond binary classification (real vs. fake) by incorporating generator identity as distinct classes. This approach involves training the model to not only identify whether an image is a deepfake, but also to determine which generative model-such as StyleGAN2, DeepFaceLab, or FaceSwap-was used to create it. By explicitly modeling the unique artifacts and characteristics introduced by each generator, the model achieves a more granular understanding of forgery techniques. This enhanced discriminatory power improves the model’s ability to generalize to previously unseen deepfakes, even those generated by novel or evolving techniques, and allows for attribution of the forgery source.
Preserving Knowledge: Combating Catastrophic Forgetting
Continual learning is a machine learning paradigm designed to overcome the limitations of traditional models which often experience “catastrophic forgetting” – a rapid degradation in performance on previously learned tasks when exposed to new data. Unlike standard training which assumes a fixed dataset, continual learning aims to incrementally acquire and retain knowledge over time, effectively mimicking human learning capabilities. This is achieved by developing algorithms that can adapt to evolving data streams without requiring retraining on the entire historical dataset, which is computationally expensive and often impractical. The core challenge lies in balancing plasticity – the ability to learn new information – with stability – the ability to retain existing knowledge. Successful continual learning systems must minimize interference between tasks and preserve previously acquired skills while effectively incorporating new information.
Replay buffers are a core technique in mitigating catastrophic forgetting within continual learning systems. These buffers function as a limited-capacity memory, storing a subset of experiences – typically state-action-reward-next state tuples – encountered during previous tasks. During the learning of new tasks, data sampled from the replay buffer is interleaved with current task data during training updates. This process effectively revisits previously learned patterns, preventing the model’s weights from shifting drastically away from configurations that supported prior performance. The size and sampling strategy of the replay buffer are critical parameters; larger buffers offer more comprehensive coverage of past experiences but increase computational cost, while strategic sampling methods can prioritize informative or rare experiences to maximize retention efficiency.
Harmonic replay is a continual learning technique designed to approximate the performance of full retraining – where a model is completely retrained on both old and new data – while substantially decreasing computational expense. This is achieved by strategically replaying past experiences, but unlike standard replay buffers which sample uniformly, harmonic replay prioritizes examples based on their contribution to the loss function. Specifically, it calculates the gradient of the loss with respect to each example and uses this to assign a “harmonic mean” importance weight. This weighting scheme ensures that examples which contribute most to reducing overall loss are replayed more frequently, leading to improved retention of previously learned information and faster adaptation to new tasks, all with a reduced computational burden compared to complete retraining. Empirical results demonstrate performance approaching that of full retraining, using significantly fewer computational resources.
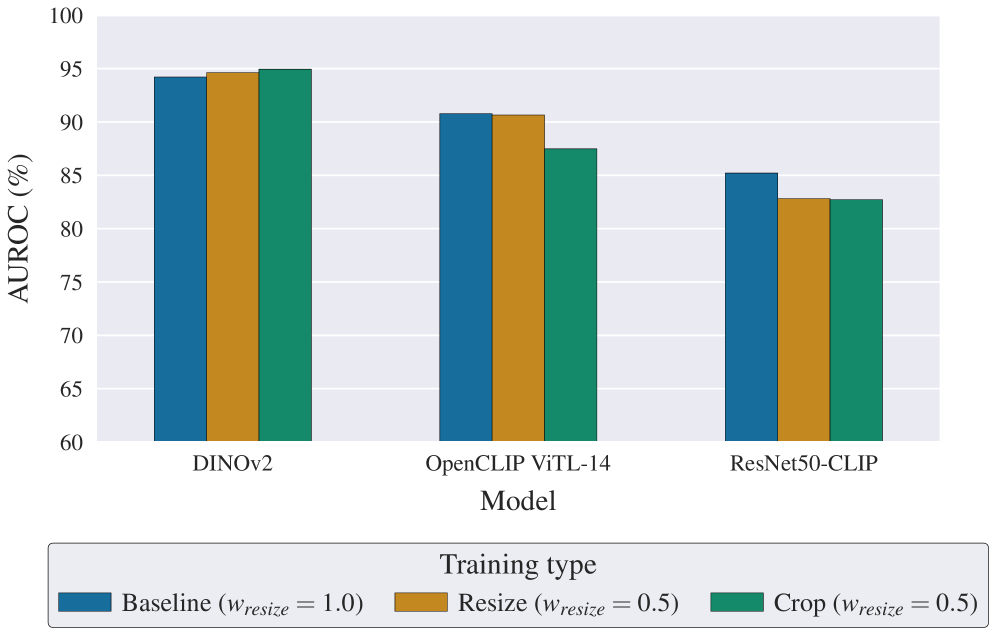
Employing binary classification as a training objective, alongside data augmentation techniques, demonstrably improves the robustness and generalization capabilities of continual learning models. Specifically, augmenting training data with transformations like JPEG compression and random cropping introduces variance, forcing the model to learn features invariant to these alterations. This approach effectively simulates real-world data imperfections and variations, reducing overfitting to the specific characteristics of the training set. The resulting models exhibit enhanced performance on unseen data and are less susceptible to catastrophic forgetting when faced with distributional shifts in subsequent tasks, achieving improved overall stability and adaptability.

AI-GenBench: A Dynamic Crucible for Deepfake Detection
Traditional deepfake detection benchmarks often rely on static datasets, failing to capture the rapidly evolving nature of forgery techniques. AI-GenBench addresses this limitation by simulating a continuous arms race between deepfake generators; new, increasingly sophisticated forgeries are introduced over time, forcing detection models to adapt and generalize beyond previously seen examples. This dynamic evaluation framework provides a more realistic assessment of a model’s robustness and its ability to maintain high performance in the face of evolving threats, ultimately offering a more representative measure of its practical utility than static benchmarks allow. By continually challenging detection systems with novel forgeries, AI-GenBench moves beyond simply identifying known patterns and assesses their capacity to recognize – and defend against – the unknown.
AI-GenBench distinguishes itself from static benchmarks by dynamically introducing novel deepfake generators throughout the evaluation process, thereby testing a detection model’s resilience and adaptability. Unlike traditional benchmarks that assess performance against a fixed set of forgeries, this framework simulates the continuous evolution of deepfake technology, demanding that models generalize beyond their training data. This approach reveals whether a detection system merely memorizes known forgery patterns or genuinely learns to identify the underlying characteristics of manipulated content, providing a more realistic and informative assessment of its long-term reliability and ability to maintain consistent performance against previously unseen threats. The continuous influx of new generators forces models to proactively adjust, highlighting vulnerabilities and pinpointing areas for improvement in the ongoing arms race against increasingly sophisticated deepfakes.
A crucial component of robust deepfake detection lies in consistent and comparable evaluation, and AI-GenBench addresses this need with a standardized pipeline. This methodology provides a common ground for assessing the performance of various detection approaches, moving beyond isolated tests on static datasets. By offering a controlled environment with evolving challenges, researchers can directly compare the strengths and weaknesses of different algorithms, fostering innovation and accelerating progress in the field. The pipeline’s rigorous structure allows for meaningful benchmarking, enabling the identification of truly effective techniques and guiding future development towards more resilient and adaptable deepfake detection systems. This standardized approach is critical for both academic research and practical deployment, ensuring that detection tools are consistently evaluated and improved over time.
Recent investigations demonstrate a state-of-the-art average Area Under the Receiver Operating Characteristic curve (AUROC) of 97.36% achieved on the AI-GenBench benchmark, signifying a substantial advancement in deepfake detection capabilities. This performance resulted from a carefully constructed methodology incorporating several key design choices; notably, a four-epoch training regimen optimized the learning process, while evaluation-based augmentation strategically expanded the training dataset with challenging examples. Furthermore, the implementation of full-image resizing in conjunction with the DINOv2 backbone facilitated a more comprehensive feature extraction, ultimately leading to enhanced discrimination between genuine and manipulated images. These combined practices establish a new benchmark for evaluating and improving the robustness of deepfake detection systems against increasingly sophisticated forgeries.

The pursuit of robust deepfake detection, as detailed in this research, benefits greatly from a mindful approach to design. It’s not simply about achieving high accuracy on a current benchmark, but about crafting systems that maintain performance as the landscape of generative models evolves. This echoes Yann LeCun’s sentiment: “The real problem we are facing is not about achieving high accuracy, but about building systems that are robust and generalize well.” The study’s emphasis on continual learning and data augmentation isn’t merely a technical exercise; it’s a commitment to elegant design – building detectors that adapt gracefully and remain effective, even as new threats emerge. Consistency in these choices, like a well-considered architectural blueprint, fosters trust in the system’s future viability.
Beyond the Mirror
The pursuit of robust deepfake detection, as this work demonstrates, isn’t merely a technical exercise in feature extraction. It’s a subtle negotiation with the inevitable. Each incremental gain in accuracy, each refined data augmentation strategy, simply buys time. The generative models will, by their nature, continue to improve, eventually eclipsing the static defenses built against them. The true challenge, then, lies not in chasing signatures of manipulation, but in developing detectors that assess the inherent plausibility of content – a shift toward understanding what should be, rather than what is, or what appears to be.
Continual learning offers a pragmatic, if temporary, reprieve, allowing detectors to adapt without wholesale retraining. However, the reliance on replay buffers, while effective, hints at a deeper limitation: the assumption that past forgeries adequately represent future threats. A more elegant solution might involve detectors that learn the underlying principles of generative modeling itself, effectively predicting the types of manipulations likely to emerge.
Ultimately, the field will be defined not by the complexity of its algorithms, but by the simplicity of its core principles. An ideal detector wouldn’t require layers of intricate processing; it would, with a single glance, reveal the dissonance between expectation and reality. Such a detector isn’t built with clever engineering; it’s discovered through a profound understanding of perception itself.
Original article: https://arxiv.org/pdf/2511.21507.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Building 3D Worlds from Words: Is Reinforcement Learning the Key?
- Spotting the Loops in Autonomous Systems
- The Best Directors of 2025
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- 20 Best TV Shows Featuring All-White Casts You Should See
- Umamusume: Gold Ship build guide
- Mel Gibson, 69, and Rosalind Ross, 35, Call It Quits After Nearly a Decade: “It’s Sad To End This Chapter in our Lives”
- Gold Rate Forecast
- Uncovering Hidden Signals in Finance with AI
2025-11-27 21:45